http://paraclete.tistory.com/entry/Manual-CentOS
intel processor
http://ark.intel.com/products/37096/Intel-Xeon-Processor-E5506-(4M-Cache-2_13-GHz-4_80-GTs-Intel-QPI)
2011년 10월 16일 일요일
2011년 10월 3일 월요일
대칭키를 이용한 ssh 로그인 for Mac/*nix
대칭키를 이용한 ssh 로그인 for Mac/*nix
ssh 프로토콜의 인증 방법은 매우 다양하며 많이 쓰이는 방식은 다음 정도가 되겠습니다.이 중 keyboard-interactive / password 인증 방식은 전부 비밀번호를 이용한 인증이고, RSA/DSA 방식은 대칭키(공개키 – 비밀키)를 이용하는 방식입니다. 공개키를 등록만 해두면 여러 개의 서버에 접속할 때 각기 따로 비밀번호를 치고 로그인을 할 필요가 없으므로 매우 편리한 방식이 되겠습니다.
- RSA or DSA key pair
- keyboard-interactive
- password
참고로 비밀키를 도둑맞을 때를 대비해서 비밀키에 암호를 걸어둘 수도 있습니다.
대칭키를 이용해서 로그인을 하도록 설정하려면 우선 대칭키를 만들어야 합니다. 대칭키를 만드는데는 ssh-keygen 이라는 툴에 어떤 방식의 암호화를 사용할 건지만 가르쳐주면 됩니다.
# ssh-keygen -t rsa위 명령어 중 위에껄 사용하면 rsa 키가 만들어지고, 아래껄 사용하면 dsa 키가 만들어집니다. 중간에 비밀번호를 입력하라고 나오는데, 여기서 비밀번호를 입력하게 되면 그 비밀번호를 이용해서 키를 암호화 를 해놓게 됩니다. (나중에 그 키를 사용하기 위해 비밀번호를 입력해야 합니다.)
# ssh-keygen -t dsa
키를 ssh 서버에 등록하려면 서버의 ~/.ssh/authorized_keys 파일에다가 아까 생성한 공개키 파일(id_rsa.pub or id_dsa.pub)의 내용을 적어주기만 하면 됩니다. 간단하죠.
만약 키에 암호를 걸지 않았다면 지금 상태만으로도 아무 문제 없이 사용할 수 있지만! 키에 암호를 걸어놓았을 경우 ssh로 접속을 시도할 때마다 비밀키를 읽어오기 위해 비밀번호를 물어볼 것입니다. 비밀번호를 치는게 귀찮아서 대칭키 기반 로그인을 설정한건데 이러면 의미가 없겠죠!
이럴 때 유용하게 써먹을 수 있는게 바로 ssh-agent입니다. 비밀키를 불러들이면, 세션이 끝날 때까지 비밀키를 계속 써먹을 수 있도록 도와주는 개념이 되겠습니다. 터미널을 닫지만 않으면 그 세션 내에서는 한 번 로딩한 비밀키를 계속해서 우려먹는거죠.
# eval `ssh-agent`사용법은 위와 같은데, 여기에 약간의 문제가 있습니다. 새로운 터미널을 연다거나 터미널을 닫았다가 다시 실행시키는 경우엔 비밀키를 새로 로딩해야 하거든요. 아까보단 많이 편해졌지만 그래도 좀 귀찮죠?
# ssh-add ~/.ssh/id_rsa
하지만 걱정하실 필요는 없습니다. 이미 발빠른 아저씨들이 keychain을 만들었거든요. keychain을 이용할 경우 이미 로딩된 키가 있는지를 확인하고 로딩된 키가 발견되면 그걸 공유하게 되므로 처음 맥/PC를 켜서 한 번만 키를 로딩하게 되면 세션을 몇 번이나 열고 닫든 상관없이 계속해서 이 키를 공유하게 되니 아주 편리하죠.
### In Gentoo Linux사용법은 위와 같습니다. Mac OS X 사용자들은 macports를 이용하면 되고, gentoo linux라면 emerge를 이용하면 되겠습니다.
# emerge keychain
### in Mac OS X
# sudo port install keychain
# echo “/usr/bin/keychain ~/.ssh/id_rsa” >> ~/.bash_profile
# echo “source ~/.keychain/`hostname`-sh > /dev/null” >> ~/.bash_profile
참고자료:
OpenSSH key management, Part 1
OpenSSH key management, Part 2
OpenSSH key management, Part 3
OpenSSH key management, Part 1 번역판
OpenSSH key management, Part 2 번역판
2011년 9월 5일 월요일
Scale up & Scale out
| Scale up | Scale out | Scale out & up | |
| 개요 | 기존 스토리지에 필요한 만큼의 용량 증가 | 용량과 성능 요구조건에 맞추기 위해 node단위 (스토리지)로 증가되고 하나의 시스템처럼 운영 | Scale up 아키텍처와 Scale out 아키텍처를 합친 개념 |
| 비용 | 컨트롤러나 네트워크 인프라 비용은 별도로 발생하지 않고 디스크만 추가됨 (상대적으로 비용이 적게 듦) | 추가된 노드들이 하나의 시스템으로 운영되기 위한 NW장비 필요, 컨트롤러도 추가 | |
| 용량 | 하나의 스토리지 컨트롤러에 붙일 수 있는 Device가 한정되어있기 때문에 용량 확장에 제약있음 | Scale up형태의 스토리지보다는 용량 확장성이 크지만 무한대로 확장하지는 않음 | |
| 성능 | Multiple storage controller의 IOPS, 대역폭 등이 합친 성능이 나옴 | ||
| 복잡성 | 심플한 구성 | 상대적으로 복잡 | |
| 가용성 | 노드가 추가될수록 가용성이 높아짐 |



http://kindstorage.tistory.com/69
[DB 성능관리 2% 채우기] ② 테이블 파티셔닝의 재발견
http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039137247&type=det
근래에 많은 기업들의 데이터베이스가 대용량화 되면서 이를 효과적으로 관리할 수 있는 방안을 찾는 것이 관리자들의 주요 업무가 됐다. 이를 위한 매우 효과적인 방안 가운데 하나가 파티셔닝이다.
일반적으로 단순한 명령어 위주로만 알려져 있지만 실제 현장에서 접하는 파티셔닝의 효용은 그 이상이다. 익숙한 개념이지만 그동안 제대로 알지 못했던 파티셔닝의 의미와 대표적인 활용 사례를 살펴보자.
필자는 많은 현장 사이트에서 대용량의 가치 있는 데이터들이 놀라운 능력을 보유하고 있는 데이터베이스 안에서 사용자의 무지로 인해 방치돼 있거나 잘못 사용되고 있어 역효과를 일으키는 모습을 많이 보아 왔다. 예를 들어 총 테이블 건수 1억 건이 넘는 상황에서 우리가 어떤 형태로든 건드려야 할 부분이 약 10% 정도라고 할 때 그 테이블 전체를 읽지 않고 1000만 건만 읽을 수 있게 해야 하는 것이 당연하지만 실제로는 그렇지 못한 경우를 많이 보아 왔다.
어떻게 처리해야겠다는 생각도 없이 무조건 명령어(command)부터 날리는 것이다. 그렇다면 필요한 테이블 만을 다루려면 어떻게 해야 할까. 이를 위해 필요한 개념이 바로 테이블 파티셔닝(Table Partitioning)이다.
파티셔닝은 지난 강좌에서 살펴본 사항들과 함께 어떤 자동화된 툴로 절대 해결할 수 없는 부분으로 실제로 어떤 상황에서 파티셔닝이 필요하다고 정형화된 법칙은 없다. 중소 용량의 데이터베이스에서도 상황에 따라 꼭 사용해야 하는 경우가 있고, 초대용량의 경우 파티셔닝을 쓰지 않으면 시스템 자체가 관리되지 않을 수도 있다(필자 역시 컨설팅을 하면서 이 파티셔닝을 이용해 많은 시스템을 효율적으로 운영할 수 있다는 것을 직간접적으로 체험한 바 있다).
그러나 대부분의 파티셔닝 관련 자료들은 형식적으로 파티셔닝의 종류를 나열하고 스크립트 정도를 언급하는 수준이다. 이런 식의 접근은 한계가 명확하다.
오히려 파티셔닝을 올바르게 이용하기 위해서는 먼저 데이터베이스 액세스 방식의 정확한 차이와 장단점 그리고 파티션을 이용한 풀 스캔(full scan)에 대해 정확하게 이해할 필요가 있다. 파티셔닝은 일종의 기능일 뿐이어서 스캔에 대한 정확한 이해없이는 이를 사용할 이유도, 어떻게 사용해야 할지도 전혀 알 수가 없다. 각 스캔 방식의 장단점을 알고 어떤 상황에서 어떤 스캔 방법이 유리한 지를 명확하게 이해해야 그에 대한 보완책으로서 파티셔닝의 개념이 보이기 시작한다.
파티셔닝 세계 입문
대용량 테이블이나 인덱스를 파티셔닝한다는 것은 하나의 Object를 여러 개의 세그먼트로 나눈다는 의미이다. 즉 하나의 테이블이나 인덱스가 동일한 논리적 속성을 가진 여러 개의 단위(partition)로 나누어져 각각이 PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE, STORAGE PARAMETER 등 별도의 물리적 속성을 갖는 것이다.
특히 관리해야 할 데이터가 늘어나면 성능과 스토리지 관점에서 문제가 생길 수 있는데, 이를 해결할 수 있는 효율적인 방법 가운데 하나가 곧 파티셔닝이다. 파티셔닝은 보통 다음과 같은 장점을 갖고 있다.
◆ 데이터 액세스시(특히 풀 스캔시) 액세스의 범위를 줄여 성능을 향상시킨다.
◆ 물리적으로 여러 영역으로 파티셔닝해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
◆ 각 파티션별로 백업, 복구 작업을 할 수 있다.
◆ 테이블의 파티션 단위로 디스크 I/O를 분산해 부하를 줄일 수 있다.
오라클 DBMS에서 제공하는 파티셔닝 방식에는 레인지(range) 파티셔닝, 해시(hash) 파티셔닝, 리스트(list) 파티셔닝, 컴포지트(composite) 파티셔닝(레인지-해시, 레인지-리스트) 등이 있다.
특정 컬럼 값을 기준으로 분할하는 레인지 파티셔닝
레인지 파티셔닝은 어떤 특정 컬럼의 정렬 값을 기준으로 분할하는 것이다. 주로 순차적인(historical) 데이터를 관리하는 테이블에 많이 사용된다. 예를 들면 ‘가입계약’이라는 테이블이 있고 여기에 몇 년 동안의 데이터가 쌓여 있다면, 보통 5년치 데이터만 관리하고 이 가운데 자주 액세스하는 하는 것은 최근 1~2년 정도가 일반적이다.
따라서 이를 년별, 월별로 파티셔닝하고 애플리케이션의 SQL을 조정해 전체 데이터가 아닌 최근 정보를 가지고 있는 파티션만 액세스하도록 하면 전체 데이터베이스의 성능을 향상시킬 수 있다. 일부 사례의 경우 가입계약_1999, 가입계약_2000처럼 월별 또는 년별로 테이블을 따로 만들어 사용하기도 했지만 실제로 쓰는 데 불편한 점이 많고 액세스하는 SQL이 복잡해지는 단점이 있다. 다음은 레인지 파티션을 만드는 DDL(Data Definition Language) 스크립트다.
CREATE TABLE CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(9), …… )
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
(PARTITION PAR_200307 VALUES LESS THAN (‘20030801’),
PARTITION PAR_200308 VALUES LESS THAN (‘20030901’), …… )
PARTITION BY RANGE (COLUMN_LIST)는 특정 컬럼을 기준으로 파티셔닝을 할 것인지를 결정하는 것이고, VALUES LESS THAN (VALUE_LIST)는 해당 파티션이 어느 범위에 포함될 것인지 상한을 정하는 것이다. PARTITION BY RANGE에 나타나는 COLUMN_LIST를 파티셔닝 컬럼이라고 하며 이 값이 파티셔닝 키를 형성한다.
파티셔닝 컬럼은 결합 인덱스처럼 최대 16개까지 지정할 수 있다. VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 상한 값으로, 여기 지정된 값보다 작은 값만을 저장하겠다는 의미이다. 이런 스크립트에서 지정한 물리적 속성들은 각 파티션들이 생성될 때 개별적으로 물리적 속성을 지정하지 않으면 각 파티션들은 이러한 속성 값을 적용 받게 된다.
오직 성능 향상, 해시 파티셔닝
해시 파티셔닝은 특정 컬럼 값에 해시 함수를 적용해 분할하는 방식으로, 데이터의 관리 목적보다는 성능 향상에 초점을 맞춘 개념이다. 레인지 파티셔닝은 각 범위에 따라 데이터 양이 일정치 않아 분포도가 일정치 않은 단점이 있는데, 해시 파티셔닝을 이런 단점을 보완해 일정한 분포를 가진 파티션으로 나누고, 균등한 분포도를 가질 수 있도록 조율해 병렬 프로세싱으로 성능을 높인다. 실제로 분포도를 정의하기 어려운 테이블을 파티셔닝을 할 때 많이 이용하고 2의 배수 개수로 파티셔닝하는 것이 일반적이다.
해시 파티셔닝으로 구분된 파티션들은 동일한 논리, 물리적 속성을 가지다(단 테이블스페이스(tablespace)는 유일하게 파티션별로 지정할 수 있다). 또한 레인지 파티션과 달리 각 파티션에 지정된 값들을 DBMS가 결정하므로 각 파티션에 어떤 값들이 들어 있는지를 알 수 없다. 그러나 대용량의 분포도가 일정치 않은 테이블을 마이그레이션할 때는 프로그램 병렬 방식과 함께 유용하게 사용할 수 있다. 다음은 해시 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE CONTRACT
( SERIAL NUMBER, CODE VARCHAR2(4), ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY HASH(SERIAL)
(PARTITION PAR_HASH_1 TABLESPACE TBS2,
PARTITION PAR_HASH_2 TABLESPACE TBS3, ……)
함께 쓰일 때 더욱 강력한 리스트 파티셔닝
리스트 파티셔닝은 특정 컬럼의 특정 값을 기준으로 파티셔닝을 하는 방식이다. 주로 이질적인(distinct) 값이 많지 않고 분포도가 비슷하며 다양한 SQL의 액세스 패스에서 해당 컬럼의 조건이 많이 들어오는 경우 유용하게 사용된다. 예를 들어 ‘서비스 계약’이라는 테이블이 있고 서비스를 최초 가입한 대리점을 ‘가입 대리점’, 변경사항을 처리한 대리점을 ‘처리 대리점’이라고 한다면 모든 서비스의 가입, 해지, 전환 등의 처리 데이터에는 이 두 대리점이 존재한다. 테이블 구조를 보면 다음과 같다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), ……)
즉 I_DLR_IND(대리점 구분)라는 컬럼이 존재하고 ‘A’일 때는 ‘가입 대리점’, ‘S’일 때는 ‘처리 대리점“이라고 할 때 대부분의 조회 패턴에는 가입 대리점 또는 처리 대리점에 해당하는 값이 들어오기 마련이다. 이럴 때 I_DLR_IND로 리스트 파티셔닝을 한다면 어떨까. 즉 집합의 서브 타입을 분류할 때 리스트 파티션은 매우 유용하다. 지금 예로 든 것은 단편적인 것에 불과하지만 리스트 파티셔닝의 위력은 강력하다. 특히 컴포지트 파티션에서 레인지 파티션과 함께 사용하면 전체 데이터베이스의 성능을 크게 향상시킬수 있다. 다음은 리스트 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY LIST (I_DLR_IND)
(PARTITION PAR_A VALUES (‘A’), PARTITION PAR_S VALUES (‘S’))
PARTITION BY LIST에 나타나는 COLUMN_LIST는 파티셔닝 컬럼으로 파티션 키에 해당하고(단 단일 컬럼만 지정할 수 있다), VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 값이다. 여기에 나타낸 값에 해당하는 행들을 저장하겠다는 의미가 된다.
레인지의 장점을 그대로, 레인지-해시 컴포지트 파티셔닝
레인지-해시 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각각의 파티션 내에서 해시 방식으로 서브 파트셔닝을 하는 방식이다. 서브 파티션이 독립된 세그먼트가 되는 것이 특징으로, 다음과 같은 장점이 있다.
◆ 관리와 성능 등 레인지 파티션의 장점을 그대로 수용한다.
◆ 해시 파티션의 이점인 데이터 균등 배치와 병렬화
◆ 서브 파티션에 특정 테이블스페이스를 지정할 수 있다.
◆ 서브 파티션별로 풀 스캔을 할 수 있어 스캔 범위를 줄여 성능을 향상시킨다.
레인지 파티션에서 해당 테이블이 단지 논리적인 구조이고 실제 데이터는 파티셔닝된 세그먼트에 저장됐던 것처럼 컴포지트 파티션에서도 해당 테이블과 파티셔닝된 테이블은 단지 파티셔닝을 위한 논리적인 구조일 뿐이다. 데이터는 가장 하위에 위치한 서브 파티션 영역에 저장된다. 다음은 레인지-해시 컴포지트 파티션을 생성하는 DDL 스크립트이다. PARTITION BY RANGE (I_YYYYMMDD)에 의해 레인지로 파티션을 한 후 SUBPARTITION BY HASH에 의해 서브 파티셔닝을 수행했음을 알 수 있다.
CREATE TABE TB_RANGE_HASH
(I_YYYYMMDD VARCHAR2(8), I_SERIAL NUMBER, SALE_PRICE NUMBER, ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY HASH (I_SERIAL)
(PARTITION SALES_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION SALES_1997_Q1 TABLESPACE TBS2,
SUBPARTITION SALES_1997_Q2 TABLESPACE TBS3), ……)
레인지-리스트 컴포지트 파티셔닝
레인지-리스트 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각 파티션 안에서 리스트 방식을 이용해 서브 파티셔닝하는 방식이다(이때 서브 파티션은 독립된 세그먼트가 된다). 레인지-리스트 컴포지트 파티션은 레인지-해시 컴포지트 파티션과 비슷하지만 서브 파티션이 리스트 파티션이라는 점이 다르다. 실제 업무에서는 레인지-해시보다 유용한 면이 많다. 다음은 레인지-리스트 컴포지트 파티션을 생성하는 DDL 스크립트이다.
CREATE TABLE TB_RANGE_LIST (
I_YYYYMMDD VARCHAR2(8), I_AGR_IND VARCHAR2(2), I_DELAER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0 MAXEXTENTS UNLIMITED)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY LIST (I_AGR_IND)
(PARTITION PAR_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION PAR_1997_A VALUES (‘A’), SUBPARTITION PAR_1997_A VALUES (‘S’)),
……)
파티션된 인덱스의 참뜻
‘파티션된 인덱스(partitioned index)’라고 하면 대부분의 개발자들은 로컬 인덱스를 떠올린다. 또한 파티션된 테이블에서만 쓰이는 것으로 생각한다. 그러나 이것은 명백한 오산이다. 파티션된 인덱스는 파티션된 테이블과 별개의 것으로, 단지 많은 상호 연관을 갖고 있을 뿐이다. 파티션된 인덱스는 문자 그대로 인덱스를 파티셔닝한 것으로, 해당 테이블이 파티션된 테이블이든 파티션되지 않은(non-partitioned) 테이블이든 상관없이 만들 수 있다.
예를 들면 ‘EMP’ 테이블의 크기가 상당히 크고 파티션되지 않은 일반 테이블일 경우 다음과 같은 과정을 통해 파티션된 인덱스를 만들 수 있다. 이를 ‘Global Prefixed Partitioned Index’라고 부르는데, 파티션 인덱스와 마찬가지로 대용량 데이터 환경에서 성능을 높이고 관리를 편리하게 하기 위해서다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
파티션된 인덱스가 유용한 이유는, 앞서 파티션의 개념에서 설명한 것처럼 하나의 인덱스를 여러 개의 독립적인 물리 속성을 가진 세그먼트로 나누어 생성, 관리할 수 있기 때문이다. 오라클 DBMS에서 제공하는 인덱스는 글로벌/로컬 인덱스와 Prefixed/Non-Prefixed 인덱스로 분류된다.
파티션된 인덱스와 일반 인덱스 사이의 차이점은 파티션 테이블과 일반 테이블의 그것과 동일하다. 인덱스는 인덱스 컬럼과 Rowid 순으로 값이 정렬되는데, 이런 특성은 파티션 인덱스에서도 동일하다. 많은 개발자들이 파티션된 인덱스는 전체 테이블 값이 정렬되지 않는다고 생각하지 하지만 이것은 사실과 다르다. 글로벌 파티션된 인덱스의 경우 테이블에 대해 값 정렬이 보장돼 있으며, 인덱스도 파티션별로 독립적으로 관리할 수 있다. 두 가지 방식의 차이는 <그림 1>과 같다.
파티션되지 않은 인덱스는 하나의 루트(root) 노드에서 리프(leaf) 노드까지 전체적인 밸런스를 유지하는 구조이고, 파티션 인덱스는 파티션 별로 독립적인 루트 노드와 리프 노드를 갖고 있음을 알 수 있다. 따라서 파티션되지 않으면 대용량 테이블에서는 글로벌 인덱스의 깊이(depth)가 매우 깊어질 수 있는 단점이 있다.
반면 파티션된 인덱스는 각 파티션별 깊이가 일반 인덱스의 깊이보다 얕고 인덱스도 파티션 별로 할 수 있어 병렬 프로세싱을 이용한 인덱스 관리에 매우 효과적이다.
그렇다면 글로벌 인덱스와 로컬 인덱스는 어떤 차이가 있는 것일까? 많은 개발자들이 파티션됐는지 여부로 판단하지만 이것은 잘못된 생각이다. 앞서 설명한 것처럼 글로벌 인덱스도 파티셔닝할 수 있으며, 이를 파티션별로 관리할 수도 있다. 글로벌 인덱스와 로컬 인덱스의 가장 큰 차이는 ‘정렬’이다. 즉 글로벌 인덱스는 테이블 전체에 대해 인덱스된 컬럼과 Rowid 순으로 정렬되고, 로컬 인덱스는 해당 파티션 내에서만 인덱스된 컬럼과 Rowid 순으로 정렬된다.
또한 로컬 인덱스는 ‘Local’이라는 말에서 알 수 있듯이 지역적인 인덱스로, 해당 테이블(base table)의 파티션 키로 파티셔닝된 인덱스다. 일반적으로 로컬 인덱스의 구성 컬럼에 반드시 파티션 키가 포함돼야 가능한 것으로 알려져 있지만 로컬 인덱스에는 파티션 키가 포함되어 있지 않아도 사용할 수 있다. 다음 예제를 보자. PACKAGE_DLR_IDX1 인덱스의 구성 컬럼에 테이블 파티션 키인 I_DLR_IND가 포함되지 않아도 검색조건에 I_DLR_IND = ‘C’라는 검색 조건이 있기 때문에 해당 파티션의 로컬 인덱스를 이용하는 것을 알 수 있다.
글로벌 인덱스는 전역적인 인덱스로, 기본적으로는 파티션되지 않은 인덱스이다. 대부분의 개발자들은 글로벌 인덱스를 파티셔닝해 사용할 생각을 하지 못하는데, 대용량 테이블에서 인덱스 관리의 효율성을 높이고 인덱스 검색 성능을 높이기 위해서는 이를 파티셔닝하는 것이 좋다. 글로벌 인덱스는 기본 테이블의 파티션 키와 무관하게 파티셔닝하는 것으로 설사 기본 테이블의 파티션 키로 글로벌 인덱스를 파티셔닝했다고 해도 로컬 인덱스처럼 동일파티셔닝(equipartitioning)된 개념이 아니므로 테이블 DDL시 전체 인덱스를 다시 생성해야 한다.
그렇다면 글로벌 파티션 인덱스의 인덱스 컬럼 값은 어떻게 전체 테이블에 대해 정렬을 보장하는 것일까. 예를 들어 5000만 건의 파티션되지 않은 EMP 테이블을 부서번호에 따라 파티셔닝했다고 가정하면 다음과 같다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RAGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (‘MAXVALE’) TABLESPACE TBS2,
<그림 2>는 Global Prefixed Partitioned 인덱스의 구조다. Prefixed와 Non-Prefixed는 인덱스 파티셔닝 키가 인덱스의 선두 컬럼으로 오는가 그렇지 않은가의 차이가 있다. <그림 2>에서도 ‘Prefixed’란 인덱스의 파티션 키(DEPTNO)가 인덱스 선두 컬럼(DEPTNO)이 되는 것을 알 수 있다. 글로벌 인덱스의 경우 모든 인덱스 컬럼 값이 정렬돼 있다. 각 인덱스 파티션의 루트 블럭(root block)에 들어가는 값들이 인덱스 파티션에 따라 정렬되기 때문에 자연적으로 리프 블럭(leaf block)에 들어가는 모든 값들도 정렬되는 것이다. 반면 Global Non-Prefixed 인덱스를 파티셔닝하면 레인지 파티셔닝 방식으로만 가능하다. 이것은 정렬 때문인데, 레인지 파티션은 정렬 기능을 이용해 파티셔닝 키 자체를 생성하는데 반해 다른 파티셔닝 방식은 정렬과 상관없이 수행하기 때문이다.
로컬 인덱스는 Prefixed 인덱스와 Non-Prefixed 인덱스를 모두 지원한다. 로컬 인덱스는 기본적으로 현재 테이블의 파티션 키가 인덱스의 파티션 키가 되기 때문에 인덱스 컬럼에 현재 테이블의 파티션 키가 포함되지 않아도 인덱스를 생성할 수 있다. 또한 인덱스 컬럼 값의 정렬이 전체 테이블에 대해 보장된 것도 아니기 때문에 인덱스 파티션 키가 인덱스의 선두 컬럼이 될 필요가 없다. 또한 Non-Partitioned 인덱스이든 파티션 인덱스든 상관없이 인덱스를 이용하고자 할 때는 무조건 인덱스 파티션 키를 조회해야 하는 글로벌 인덱스와 달리 로컬 인덱스는 조회 검색조건에 파티션 키가 들어올 수도 있고 들어오지 않을 수도 있다.
대용량 DB 테이블과 인덱스 전략
파티션 인덱스 전략은 파티션 테이블과 밀접하게 연관되어 수립해야 하지만 여기서는 파티션 인덱스를 위주로 이야기를 풀어본다. 먼저 인덱스 크기에 대한 논의는 기본적으로 테이블보다는 훨씬 작게 생성, 관리하는 것이 원칙이다. 따라서 중소 용량의 데이터베이스 환경에서는 파티션 인덱스의 유용성을 따질 필요가 없다. 단 중소 용량의 데이터 환경일 경우에서도 테이블이 파티셔닝돼 있다면 파티션 인덱스를 고려해야 한다. 또한 기본적으로 파티션되지 않은 인덱스(일반 인덱스) 전략을 기본으로 해 테이블이 파티셔닝 된 경우와 인덱스를 파티셔닝했을 때의 장점을 비교해 보아야 한다.
먼저 테이블 파티션 키가 항상 ‘=’로 들어오는 경우 또는 파티션 범위가 크지 않은 경우에는 로컬 인덱스가 최상이다. 인덱스 컬럼의 순서와 구성은 액세스 패스에 따라 생성하면 되지만 최대한 가볍게 생성하는 것이 좋다. 기본 테이블의 파티션 키는 반드시 포함될 필요가 없으나, 테이블이 레인지 파티션이고 한 파티션 범위 안에서 파티션 키의 분포도가 좋을 경우 이를 포함하는 것을 고려해 볼만하다. 이렇게 하면 각 파티션당 인덱스가 파티션되지 않았을 때보다 가벼워지고 데이터 마이그레이션을 할 때도 테이블 파티션과 인덱스 파티션이 동일하므로 exchange, add, drop, split 등 파티션별 관리도 용이하다.
또한 빠른 응답 시간을 요구하는 환경에서 대용량 파티션 테이블의 조회 조건에 파티션 키가 들어오지 않을 가능성이 있다면 파티션 글로벌 인덱스를 고려해 볼만하다. 이렇게 하면 파티션되지 않은 글로벌 인덱스와 달리 레인지 파티션 별로 인덱스가 가벼워지는 장점이 있고, 레인지 파티션 별로 인덱스 split와 rebuild 명령을 독립적으로 수행할 수 있다. 컬럼 분포도에 따른 파티셔닝이나 민감한(critical)한 상수 레인지에 대해서는 파티션을 독립적으로 생성해 인덱스 크기를 줄임으로써 인덱스 검색 시간을 줄일 수 있는 이점도 있다.
exchange는 파티션된 테이블의 특정 파티션과 파티션되지 않은 일반 테이블 간의 구조를 서로 바꾸는 것으로, 대용량의 파티션된 테이블을 관리하는 데 상당한 효과가 있다. <그림 2>와 같이 데이터가 없는 새로운 데이터 테이블과 데이터가 들어 있는 파티션 2를 exchange하면 파티션 2에 해당하는 디렉토리 정보가 새로운 데이터로 바뀌고 새 테이블 데이터에는 데이터가 들어간다. 이것은 실제 데이터가 이동하는 것이 아니라 데이터를 저장하는 테이블 정보만을 업데이트하는 것이다. 한 가지 주의할 점은 exchange하고자 하는 파티션과 테이블의 구조가 같아야 하고 속성들의 특성도 같아야 한다는 사실이다.
exchange의 기본적인 문법은 다음과 같다.
Alter table Tb_Partition
Exchange partition par_200306
With table Tb_Exchange
(Without validation Including indexes)
한편 파티션된 대용량 테이블에 split 함수를 실행하면 많은 시간이 걸린다. 이럴 때 exchange 기능을 이용하면 빠르고 안전하게 작업할 수 있다. <그림 4>에서 보는 것처럼 split를 해야 하는 파티션을 exchange에 의해 빈 공간으로 만든 다음 split을 하고 다시 데이터를 채우기 위해 split하는 것이다. 이렇게 하면 대용량의 데이터라도 매우 빠른 시간내에 split 작업을 수행할 수 있다.
한편 대부분의 DBA들과 개발자들은 동일한 테이블을 생성할 때 create table ~ as select 구문을 이용한다. 대용량의 데이터일 경우 parallel 옵션을 줘 생성하기도 한다. 만약 1억 건의 테이블을 그대로 생성한다고 할 때 어떤 방법이 효과적일까. 이렇게 파티션된 대용량 테이블을 생성할 때는 exchange, program parallel 방법을 사용하는 것이 바람직하다.
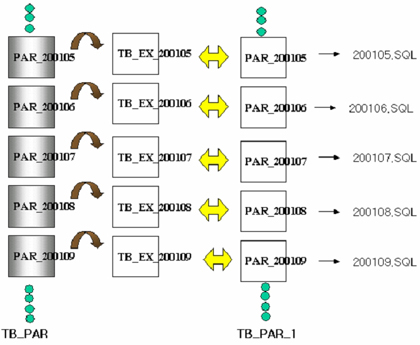
<그림 5>는 이 과정을 도식화한 것이다. 먼저 생성할 TB_PART_1 테이블의 빈껍데기를 만든다. 대용량의 파티션된 테이블의 파티션 각각을 create table ~ as select 구문의 parallel 옵션을 이용해 각 테이블로 생성한다. 이후 미리 생성해 놓은 TB_PART_1 테이블의 파티션과 만들어 놓은 테이블들을 exchange하는 것이다. 이때 파티션별로 200105.sql, 200106.sql, 200107.sql…… 형식으로 만들어 놓고 이 프로그램들을 동시에 실행하면(program parallel) 극적인 효과를 볼 수 있다.
이번엔 데이터 마이그레이션에 대해 살펴 보자. 원격으로 데이터를 옮겨야 할 때 보통 database link를 이용한다. 네트워크를 통해 데이터를 옮기면 직렬(serial)로 데이터가 이동되므로 속도가 현저하게 떨어지기 때문이다. 따라서 소스 테이블을 파티셔닝하고 해당 파티션을 액세스하는 프로그램을 각각 띄워 병렬 프로세싱을 하게 되면 매우 빠른 속도로 데이터를 옮길 수 있다.
소스 테이블을 파티셔닝할 수 있는 상황이라면 테이블의 분포를 보고 레인지나 리스트 방식으로 파티셔닝할 수 있고, 일정한 분포가 존재하지 않는 테이블이라면 해시 파티셔닝으로 분포도를 고르게 나눈 다음 해당 파티션을 읽는 뷰를 액세스해 데이터를 옮기는 것이 좋다.
예를 들어 다음은 중대형 정도 크기인 약 2700만 건의 회원 테이블을 옮기는 DDL 스크립트다. 앞서 언급한 대로 이를 바로 database link를 이용해 처리하면 네트워크의 속도가 떨어져 엄청난 시간이 소요된다. 그러나 이것을 일반 테이블을 여러 개로 파티션을 나누어서 파티션과 병렬 처리하면 성능이 크게 향상된다. 작업 순서는 다음과 같다.
create table t_cust_hash
storage (initial 5M next 5M pctincrease 0)
partition by hash(mem_no)
(
partition par_hash_1 TABLESPACE TS_DATA,
partition par_hash_2 TABLESPACE TS_DATA,
partition par_hash_3 TABLESPACE TS_DATA,
partition par_hash_4 TABLESPACE TS_DATA,
partition par_hash_6 TABLESPACE TS_DATA,
partition par_hash_7 TABLESPACE TS_DATA,
partition par_hash_8 TABLESPACE TS_DATA,
partition par_hash_9 TABLESPACE TS_DATA,
partition par_hash_10 TABLESPACE TS_DATA,
)
nologging
as
select /*+ parallel(x 10) */ * from t_cust x
이제 다음과 같이 소스 테이블 뷰 생성한 후
create or replace view t_cust_1
as select * from t_cust_hash partition (par_hash_1);
create or replace view t_cust_2
as select * from t_cust_hash partition (par_hash_2);
create or replace view t_cust_3
as select * from t_cust_hash partition (par_hash_3)
……
다음과 같이 프로그램 패러럴(program parallel) 작업을 동시에 실행한다.
T_cust_1.sql
create table t_cust_1
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_1@remote x;
T_cust_2.sql
create table t_cust_2
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_2@remote x
이것은 단적인 예에 지나지 않는다. 활용할 수 있는 사례는 얼마든지 있을 것이다. 한편 인덱스는 전체 데이터에 대해 해당 컬럼의 값으로 정렬하기 때문에 대용량 테이블의 경우 create, rebuild 명령을 실행할 때 많은 시간이 필요하다. 이때 파티션된 인덱스를 만들면 인덱스의 생성과 관리를 더 활용적으로 할 수 있다. 다음은 파티션된 인덱스를 Unusable로 생성한 사례다(로컬/글로벌 파티션된 인덱스).
먼저 파티션 인덱스를 ‘unusable’ 옵션을 이용해 생성한다. 실제 데이터를 정렬해 만드는 것이 아니라 일종의 껍데기를 만드는 과정이다. 이제 앞서 살펴본 병렬 처리를 이용해 여러 파티션을 동시에 rebuild를 하면 대용량 데이터라도 빠른 시간에 인덱스를 생성할 수 있다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
UNUSABLE;
이제 파티션별로 index1.sql, index2.sql 등을 독립적으로 병렬 실행한다.
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_10 PARALLEL 4; ---‘ index1.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_20 PARALLEL 4; ---‘ index2.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_30 PARALLEL 4; ---‘ index3.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_40 PARALLEL 4; ---‘ index4.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_MAX PARALLEL 4; ---‘ index5.sql
지금까지 테이블 파티셔닝에 대해 다뤄봤다. 자동화된 성능관리 툴로 커버할 수 없는 영역을 살펴보고 있으나 가장 중요한 것은 데이터베이스 액세스 개념에 대해 정확하게 이해하는 것이다. 많은 사람들이 파티셔닝을 알고 있지만 정확하게 사용하고 있지 못하는 현실이 아타까울 때가 많다. 그러나 이 점은 역설적으로 파티셔닝의 매력이기도 하다. 노력하는 데이터베이스 관리자 만이 도전해 볼 수 있는 영역이 바로 ‘파티셔닝’ 분야이기 때문이다.@
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.
근래에 많은 기업들의 데이터베이스가 대용량화 되면서 이를 효과적으로 관리할 수 있는 방안을 찾는 것이 관리자들의 주요 업무가 됐다. 이를 위한 매우 효과적인 방안 가운데 하나가 파티셔닝이다.
일반적으로 단순한 명령어 위주로만 알려져 있지만 실제 현장에서 접하는 파티셔닝의 효용은 그 이상이다. 익숙한 개념이지만 그동안 제대로 알지 못했던 파티셔닝의 의미와 대표적인 활용 사례를 살펴보자.
필자는 많은 현장 사이트에서 대용량의 가치 있는 데이터들이 놀라운 능력을 보유하고 있는 데이터베이스 안에서 사용자의 무지로 인해 방치돼 있거나 잘못 사용되고 있어 역효과를 일으키는 모습을 많이 보아 왔다. 예를 들어 총 테이블 건수 1억 건이 넘는 상황에서 우리가 어떤 형태로든 건드려야 할 부분이 약 10% 정도라고 할 때 그 테이블 전체를 읽지 않고 1000만 건만 읽을 수 있게 해야 하는 것이 당연하지만 실제로는 그렇지 못한 경우를 많이 보아 왔다.
어떻게 처리해야겠다는 생각도 없이 무조건 명령어(command)부터 날리는 것이다. 그렇다면 필요한 테이블 만을 다루려면 어떻게 해야 할까. 이를 위해 필요한 개념이 바로 테이블 파티셔닝(Table Partitioning)이다.
파티셔닝은 지난 강좌에서 살펴본 사항들과 함께 어떤 자동화된 툴로 절대 해결할 수 없는 부분으로 실제로 어떤 상황에서 파티셔닝이 필요하다고 정형화된 법칙은 없다. 중소 용량의 데이터베이스에서도 상황에 따라 꼭 사용해야 하는 경우가 있고, 초대용량의 경우 파티셔닝을 쓰지 않으면 시스템 자체가 관리되지 않을 수도 있다(필자 역시 컨설팅을 하면서 이 파티셔닝을 이용해 많은 시스템을 효율적으로 운영할 수 있다는 것을 직간접적으로 체험한 바 있다).
그러나 대부분의 파티셔닝 관련 자료들은 형식적으로 파티셔닝의 종류를 나열하고 스크립트 정도를 언급하는 수준이다. 이런 식의 접근은 한계가 명확하다.
오히려 파티셔닝을 올바르게 이용하기 위해서는 먼저 데이터베이스 액세스 방식의 정확한 차이와 장단점 그리고 파티션을 이용한 풀 스캔(full scan)에 대해 정확하게 이해할 필요가 있다. 파티셔닝은 일종의 기능일 뿐이어서 스캔에 대한 정확한 이해없이는 이를 사용할 이유도, 어떻게 사용해야 할지도 전혀 알 수가 없다. 각 스캔 방식의 장단점을 알고 어떤 상황에서 어떤 스캔 방법이 유리한 지를 명확하게 이해해야 그에 대한 보완책으로서 파티셔닝의 개념이 보이기 시작한다.
파티셔닝 세계 입문
대용량 테이블이나 인덱스를 파티셔닝한다는 것은 하나의 Object를 여러 개의 세그먼트로 나눈다는 의미이다. 즉 하나의 테이블이나 인덱스가 동일한 논리적 속성을 가진 여러 개의 단위(partition)로 나누어져 각각이 PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE, STORAGE PARAMETER 등 별도의 물리적 속성을 갖는 것이다.
특히 관리해야 할 데이터가 늘어나면 성능과 스토리지 관점에서 문제가 생길 수 있는데, 이를 해결할 수 있는 효율적인 방법 가운데 하나가 곧 파티셔닝이다. 파티셔닝은 보통 다음과 같은 장점을 갖고 있다.
◆ 데이터 액세스시(특히 풀 스캔시) 액세스의 범위를 줄여 성능을 향상시킨다.
◆ 물리적으로 여러 영역으로 파티셔닝해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
◆ 각 파티션별로 백업, 복구 작업을 할 수 있다.
◆ 테이블의 파티션 단위로 디스크 I/O를 분산해 부하를 줄일 수 있다.
오라클 DBMS에서 제공하는 파티셔닝 방식에는 레인지(range) 파티셔닝, 해시(hash) 파티셔닝, 리스트(list) 파티셔닝, 컴포지트(composite) 파티셔닝(레인지-해시, 레인지-리스트) 등이 있다.
특정 컬럼 값을 기준으로 분할하는 레인지 파티셔닝
레인지 파티셔닝은 어떤 특정 컬럼의 정렬 값을 기준으로 분할하는 것이다. 주로 순차적인(historical) 데이터를 관리하는 테이블에 많이 사용된다. 예를 들면 ‘가입계약’이라는 테이블이 있고 여기에 몇 년 동안의 데이터가 쌓여 있다면, 보통 5년치 데이터만 관리하고 이 가운데 자주 액세스하는 하는 것은 최근 1~2년 정도가 일반적이다.
따라서 이를 년별, 월별로 파티셔닝하고 애플리케이션의 SQL을 조정해 전체 데이터가 아닌 최근 정보를 가지고 있는 파티션만 액세스하도록 하면 전체 데이터베이스의 성능을 향상시킬 수 있다. 일부 사례의 경우 가입계약_1999, 가입계약_2000처럼 월별 또는 년별로 테이블을 따로 만들어 사용하기도 했지만 실제로 쓰는 데 불편한 점이 많고 액세스하는 SQL이 복잡해지는 단점이 있다. 다음은 레인지 파티션을 만드는 DDL(Data Definition Language) 스크립트다.
CREATE TABLE CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(9), …… )
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
(PARTITION PAR_200307 VALUES LESS THAN (‘20030801’),
PARTITION PAR_200308 VALUES LESS THAN (‘20030901’), …… )
PARTITION BY RANGE (COLUMN_LIST)는 특정 컬럼을 기준으로 파티셔닝을 할 것인지를 결정하는 것이고, VALUES LESS THAN (VALUE_LIST)는 해당 파티션이 어느 범위에 포함될 것인지 상한을 정하는 것이다. PARTITION BY RANGE에 나타나는 COLUMN_LIST를 파티셔닝 컬럼이라고 하며 이 값이 파티셔닝 키를 형성한다.
파티셔닝 컬럼은 결합 인덱스처럼 최대 16개까지 지정할 수 있다. VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 상한 값으로, 여기 지정된 값보다 작은 값만을 저장하겠다는 의미이다. 이런 스크립트에서 지정한 물리적 속성들은 각 파티션들이 생성될 때 개별적으로 물리적 속성을 지정하지 않으면 각 파티션들은 이러한 속성 값을 적용 받게 된다.
오직 성능 향상, 해시 파티셔닝
해시 파티셔닝은 특정 컬럼 값에 해시 함수를 적용해 분할하는 방식으로, 데이터의 관리 목적보다는 성능 향상에 초점을 맞춘 개념이다. 레인지 파티셔닝은 각 범위에 따라 데이터 양이 일정치 않아 분포도가 일정치 않은 단점이 있는데, 해시 파티셔닝을 이런 단점을 보완해 일정한 분포를 가진 파티션으로 나누고, 균등한 분포도를 가질 수 있도록 조율해 병렬 프로세싱으로 성능을 높인다. 실제로 분포도를 정의하기 어려운 테이블을 파티셔닝을 할 때 많이 이용하고 2의 배수 개수로 파티셔닝하는 것이 일반적이다.
해시 파티셔닝으로 구분된 파티션들은 동일한 논리, 물리적 속성을 가지다(단 테이블스페이스(tablespace)는 유일하게 파티션별로 지정할 수 있다). 또한 레인지 파티션과 달리 각 파티션에 지정된 값들을 DBMS가 결정하므로 각 파티션에 어떤 값들이 들어 있는지를 알 수 없다. 그러나 대용량의 분포도가 일정치 않은 테이블을 마이그레이션할 때는 프로그램 병렬 방식과 함께 유용하게 사용할 수 있다. 다음은 해시 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE CONTRACT
( SERIAL NUMBER, CODE VARCHAR2(4), ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY HASH(SERIAL)
(PARTITION PAR_HASH_1 TABLESPACE TBS2,
PARTITION PAR_HASH_2 TABLESPACE TBS3, ……)
함께 쓰일 때 더욱 강력한 리스트 파티셔닝
리스트 파티셔닝은 특정 컬럼의 특정 값을 기준으로 파티셔닝을 하는 방식이다. 주로 이질적인(distinct) 값이 많지 않고 분포도가 비슷하며 다양한 SQL의 액세스 패스에서 해당 컬럼의 조건이 많이 들어오는 경우 유용하게 사용된다. 예를 들어 ‘서비스 계약’이라는 테이블이 있고 서비스를 최초 가입한 대리점을 ‘가입 대리점’, 변경사항을 처리한 대리점을 ‘처리 대리점’이라고 한다면 모든 서비스의 가입, 해지, 전환 등의 처리 데이터에는 이 두 대리점이 존재한다. 테이블 구조를 보면 다음과 같다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), ……)
즉 I_DLR_IND(대리점 구분)라는 컬럼이 존재하고 ‘A’일 때는 ‘가입 대리점’, ‘S’일 때는 ‘처리 대리점“이라고 할 때 대부분의 조회 패턴에는 가입 대리점 또는 처리 대리점에 해당하는 값이 들어오기 마련이다. 이럴 때 I_DLR_IND로 리스트 파티셔닝을 한다면 어떨까. 즉 집합의 서브 타입을 분류할 때 리스트 파티션은 매우 유용하다. 지금 예로 든 것은 단편적인 것에 불과하지만 리스트 파티셔닝의 위력은 강력하다. 특히 컴포지트 파티션에서 레인지 파티션과 함께 사용하면 전체 데이터베이스의 성능을 크게 향상시킬수 있다. 다음은 리스트 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY LIST (I_DLR_IND)
(PARTITION PAR_A VALUES (‘A’), PARTITION PAR_S VALUES (‘S’))
PARTITION BY LIST에 나타나는 COLUMN_LIST는 파티셔닝 컬럼으로 파티션 키에 해당하고(단 단일 컬럼만 지정할 수 있다), VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 값이다. 여기에 나타낸 값에 해당하는 행들을 저장하겠다는 의미가 된다.
레인지의 장점을 그대로, 레인지-해시 컴포지트 파티셔닝
레인지-해시 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각각의 파티션 내에서 해시 방식으로 서브 파트셔닝을 하는 방식이다. 서브 파티션이 독립된 세그먼트가 되는 것이 특징으로, 다음과 같은 장점이 있다.
◆ 관리와 성능 등 레인지 파티션의 장점을 그대로 수용한다.
◆ 해시 파티션의 이점인 데이터 균등 배치와 병렬화
◆ 서브 파티션에 특정 테이블스페이스를 지정할 수 있다.
◆ 서브 파티션별로 풀 스캔을 할 수 있어 스캔 범위를 줄여 성능을 향상시킨다.
레인지 파티션에서 해당 테이블이 단지 논리적인 구조이고 실제 데이터는 파티셔닝된 세그먼트에 저장됐던 것처럼 컴포지트 파티션에서도 해당 테이블과 파티셔닝된 테이블은 단지 파티셔닝을 위한 논리적인 구조일 뿐이다. 데이터는 가장 하위에 위치한 서브 파티션 영역에 저장된다. 다음은 레인지-해시 컴포지트 파티션을 생성하는 DDL 스크립트이다. PARTITION BY RANGE (I_YYYYMMDD)에 의해 레인지로 파티션을 한 후 SUBPARTITION BY HASH에 의해 서브 파티셔닝을 수행했음을 알 수 있다.
CREATE TABE TB_RANGE_HASH
(I_YYYYMMDD VARCHAR2(8), I_SERIAL NUMBER, SALE_PRICE NUMBER, ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY HASH (I_SERIAL)
(PARTITION SALES_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION SALES_1997_Q1 TABLESPACE TBS2,
SUBPARTITION SALES_1997_Q2 TABLESPACE TBS3), ……)
레인지-리스트 컴포지트 파티셔닝
레인지-리스트 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각 파티션 안에서 리스트 방식을 이용해 서브 파티셔닝하는 방식이다(이때 서브 파티션은 독립된 세그먼트가 된다). 레인지-리스트 컴포지트 파티션은 레인지-해시 컴포지트 파티션과 비슷하지만 서브 파티션이 리스트 파티션이라는 점이 다르다. 실제 업무에서는 레인지-해시보다 유용한 면이 많다. 다음은 레인지-리스트 컴포지트 파티션을 생성하는 DDL 스크립트이다.
CREATE TABLE TB_RANGE_LIST (
I_YYYYMMDD VARCHAR2(8), I_AGR_IND VARCHAR2(2), I_DELAER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0 MAXEXTENTS UNLIMITED)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY LIST (I_AGR_IND)
(PARTITION PAR_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION PAR_1997_A VALUES (‘A’), SUBPARTITION PAR_1997_A VALUES (‘S’)),
……)
파티션된 인덱스의 참뜻
‘파티션된 인덱스(partitioned index)’라고 하면 대부분의 개발자들은 로컬 인덱스를 떠올린다. 또한 파티션된 테이블에서만 쓰이는 것으로 생각한다. 그러나 이것은 명백한 오산이다. 파티션된 인덱스는 파티션된 테이블과 별개의 것으로, 단지 많은 상호 연관을 갖고 있을 뿐이다. 파티션된 인덱스는 문자 그대로 인덱스를 파티셔닝한 것으로, 해당 테이블이 파티션된 테이블이든 파티션되지 않은(non-partitioned) 테이블이든 상관없이 만들 수 있다.
예를 들면 ‘EMP’ 테이블의 크기가 상당히 크고 파티션되지 않은 일반 테이블일 경우 다음과 같은 과정을 통해 파티션된 인덱스를 만들 수 있다. 이를 ‘Global Prefixed Partitioned Index’라고 부르는데, 파티션 인덱스와 마찬가지로 대용량 데이터 환경에서 성능을 높이고 관리를 편리하게 하기 위해서다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
파티션된 인덱스가 유용한 이유는, 앞서 파티션의 개념에서 설명한 것처럼 하나의 인덱스를 여러 개의 독립적인 물리 속성을 가진 세그먼트로 나누어 생성, 관리할 수 있기 때문이다. 오라클 DBMS에서 제공하는 인덱스는 글로벌/로컬 인덱스와 Prefixed/Non-Prefixed 인덱스로 분류된다.
파티션된 인덱스와 일반 인덱스 사이의 차이점은 파티션 테이블과 일반 테이블의 그것과 동일하다. 인덱스는 인덱스 컬럼과 Rowid 순으로 값이 정렬되는데, 이런 특성은 파티션 인덱스에서도 동일하다. 많은 개발자들이 파티션된 인덱스는 전체 테이블 값이 정렬되지 않는다고 생각하지 하지만 이것은 사실과 다르다. 글로벌 파티션된 인덱스의 경우 테이블에 대해 값 정렬이 보장돼 있으며, 인덱스도 파티션별로 독립적으로 관리할 수 있다. 두 가지 방식의 차이는 <그림 1>과 같다.
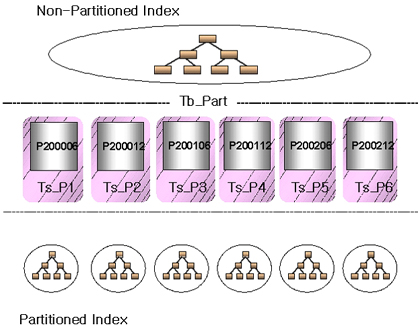 |
| <그림 1> 파티션된 인덱스와 파티션되지 않은 인덱스의 차이 |
파티션되지 않은 인덱스는 하나의 루트(root) 노드에서 리프(leaf) 노드까지 전체적인 밸런스를 유지하는 구조이고, 파티션 인덱스는 파티션 별로 독립적인 루트 노드와 리프 노드를 갖고 있음을 알 수 있다. 따라서 파티션되지 않으면 대용량 테이블에서는 글로벌 인덱스의 깊이(depth)가 매우 깊어질 수 있는 단점이 있다.
반면 파티션된 인덱스는 각 파티션별 깊이가 일반 인덱스의 깊이보다 얕고 인덱스도 파티션 별로 할 수 있어 병렬 프로세싱을 이용한 인덱스 관리에 매우 효과적이다.
그렇다면 글로벌 인덱스와 로컬 인덱스는 어떤 차이가 있는 것일까? 많은 개발자들이 파티션됐는지 여부로 판단하지만 이것은 잘못된 생각이다. 앞서 설명한 것처럼 글로벌 인덱스도 파티셔닝할 수 있으며, 이를 파티션별로 관리할 수도 있다. 글로벌 인덱스와 로컬 인덱스의 가장 큰 차이는 ‘정렬’이다. 즉 글로벌 인덱스는 테이블 전체에 대해 인덱스된 컬럼과 Rowid 순으로 정렬되고, 로컬 인덱스는 해당 파티션 내에서만 인덱스된 컬럼과 Rowid 순으로 정렬된다.
또한 로컬 인덱스는 ‘Local’이라는 말에서 알 수 있듯이 지역적인 인덱스로, 해당 테이블(base table)의 파티션 키로 파티셔닝된 인덱스다. 일반적으로 로컬 인덱스의 구성 컬럼에 반드시 파티션 키가 포함돼야 가능한 것으로 알려져 있지만 로컬 인덱스에는 파티션 키가 포함되어 있지 않아도 사용할 수 있다. 다음 예제를 보자. PACKAGE_DLR_IDX1 인덱스의 구성 컬럼에 테이블 파티션 키인 I_DLR_IND가 포함되지 않아도 검색조건에 I_DLR_IND = ‘C’라는 검색 조건이 있기 때문에 해당 파티션의 로컬 인덱스를 이용하는 것을 알 수 있다.
| select | ||||||||||||||||
| *from PACKAGE_DLR | ||||||||||||||||
| where i_package = ‘AAA’ and i_dlr_ind = ‘C’ | ||||||||||||||||
|
글로벌 인덱스는 전역적인 인덱스로, 기본적으로는 파티션되지 않은 인덱스이다. 대부분의 개발자들은 글로벌 인덱스를 파티셔닝해 사용할 생각을 하지 못하는데, 대용량 테이블에서 인덱스 관리의 효율성을 높이고 인덱스 검색 성능을 높이기 위해서는 이를 파티셔닝하는 것이 좋다. 글로벌 인덱스는 기본 테이블의 파티션 키와 무관하게 파티셔닝하는 것으로 설사 기본 테이블의 파티션 키로 글로벌 인덱스를 파티셔닝했다고 해도 로컬 인덱스처럼 동일파티셔닝(equipartitioning)된 개념이 아니므로 테이블 DDL시 전체 인덱스를 다시 생성해야 한다.
그렇다면 글로벌 파티션 인덱스의 인덱스 컬럼 값은 어떻게 전체 테이블에 대해 정렬을 보장하는 것일까. 예를 들어 5000만 건의 파티션되지 않은 EMP 테이블을 부서번호에 따라 파티셔닝했다고 가정하면 다음과 같다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RAGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (‘MAXVALE’) TABLESPACE TBS2,
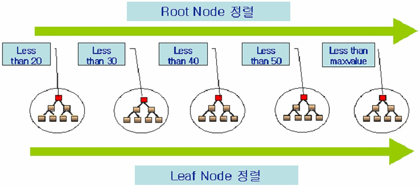 |
| <그림 2> Global Prefixed Partitioned 인덱스 |
<그림 2>는 Global Prefixed Partitioned 인덱스의 구조다. Prefixed와 Non-Prefixed는 인덱스 파티셔닝 키가 인덱스의 선두 컬럼으로 오는가 그렇지 않은가의 차이가 있다. <그림 2>에서도 ‘Prefixed’란 인덱스의 파티션 키(DEPTNO)가 인덱스 선두 컬럼(DEPTNO)이 되는 것을 알 수 있다. 글로벌 인덱스의 경우 모든 인덱스 컬럼 값이 정렬돼 있다. 각 인덱스 파티션의 루트 블럭(root block)에 들어가는 값들이 인덱스 파티션에 따라 정렬되기 때문에 자연적으로 리프 블럭(leaf block)에 들어가는 모든 값들도 정렬되는 것이다. 반면 Global Non-Prefixed 인덱스를 파티셔닝하면 레인지 파티셔닝 방식으로만 가능하다. 이것은 정렬 때문인데, 레인지 파티션은 정렬 기능을 이용해 파티셔닝 키 자체를 생성하는데 반해 다른 파티셔닝 방식은 정렬과 상관없이 수행하기 때문이다.
로컬 인덱스는 Prefixed 인덱스와 Non-Prefixed 인덱스를 모두 지원한다. 로컬 인덱스는 기본적으로 현재 테이블의 파티션 키가 인덱스의 파티션 키가 되기 때문에 인덱스 컬럼에 현재 테이블의 파티션 키가 포함되지 않아도 인덱스를 생성할 수 있다. 또한 인덱스 컬럼 값의 정렬이 전체 테이블에 대해 보장된 것도 아니기 때문에 인덱스 파티션 키가 인덱스의 선두 컬럼이 될 필요가 없다. 또한 Non-Partitioned 인덱스이든 파티션 인덱스든 상관없이 인덱스를 이용하고자 할 때는 무조건 인덱스 파티션 키를 조회해야 하는 글로벌 인덱스와 달리 로컬 인덱스는 조회 검색조건에 파티션 키가 들어올 수도 있고 들어오지 않을 수도 있다.
대용량 DB 테이블과 인덱스 전략
파티션 인덱스 전략은 파티션 테이블과 밀접하게 연관되어 수립해야 하지만 여기서는 파티션 인덱스를 위주로 이야기를 풀어본다. 먼저 인덱스 크기에 대한 논의는 기본적으로 테이블보다는 훨씬 작게 생성, 관리하는 것이 원칙이다. 따라서 중소 용량의 데이터베이스 환경에서는 파티션 인덱스의 유용성을 따질 필요가 없다. 단 중소 용량의 데이터 환경일 경우에서도 테이블이 파티셔닝돼 있다면 파티션 인덱스를 고려해야 한다. 또한 기본적으로 파티션되지 않은 인덱스(일반 인덱스) 전략을 기본으로 해 테이블이 파티셔닝 된 경우와 인덱스를 파티셔닝했을 때의 장점을 비교해 보아야 한다.
먼저 테이블 파티션 키가 항상 ‘=’로 들어오는 경우 또는 파티션 범위가 크지 않은 경우에는 로컬 인덱스가 최상이다. 인덱스 컬럼의 순서와 구성은 액세스 패스에 따라 생성하면 되지만 최대한 가볍게 생성하는 것이 좋다. 기본 테이블의 파티션 키는 반드시 포함될 필요가 없으나, 테이블이 레인지 파티션이고 한 파티션 범위 안에서 파티션 키의 분포도가 좋을 경우 이를 포함하는 것을 고려해 볼만하다. 이렇게 하면 각 파티션당 인덱스가 파티션되지 않았을 때보다 가벼워지고 데이터 마이그레이션을 할 때도 테이블 파티션과 인덱스 파티션이 동일하므로 exchange, add, drop, split 등 파티션별 관리도 용이하다.
또한 빠른 응답 시간을 요구하는 환경에서 대용량 파티션 테이블의 조회 조건에 파티션 키가 들어오지 않을 가능성이 있다면 파티션 글로벌 인덱스를 고려해 볼만하다. 이렇게 하면 파티션되지 않은 글로벌 인덱스와 달리 레인지 파티션 별로 인덱스가 가벼워지는 장점이 있고, 레인지 파티션 별로 인덱스 split와 rebuild 명령을 독립적으로 수행할 수 있다. 컬럼 분포도에 따른 파티셔닝이나 민감한(critical)한 상수 레인지에 대해서는 파티션을 독립적으로 생성해 인덱스 크기를 줄임으로써 인덱스 검색 시간을 줄일 수 있는 이점도 있다.
exchange는 파티션된 테이블의 특정 파티션과 파티션되지 않은 일반 테이블 간의 구조를 서로 바꾸는 것으로, 대용량의 파티션된 테이블을 관리하는 데 상당한 효과가 있다. <그림 2>와 같이 데이터가 없는 새로운 데이터 테이블과 데이터가 들어 있는 파티션 2를 exchange하면 파티션 2에 해당하는 디렉토리 정보가 새로운 데이터로 바뀌고 새 테이블 데이터에는 데이터가 들어간다. 이것은 실제 데이터가 이동하는 것이 아니라 데이터를 저장하는 테이블 정보만을 업데이트하는 것이다. 한 가지 주의할 점은 exchange하고자 하는 파티션과 테이블의 구조가 같아야 하고 속성들의 특성도 같아야 한다는 사실이다.
exchange의 기본적인 문법은 다음과 같다.
Alter table Tb_Partition
Exchange partition par_200306
With table Tb_Exchange
(Without validation Including indexes)
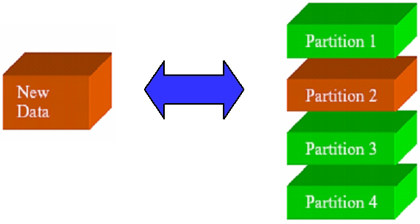 |
| <그림 3> 대용량 DB에서 exchange 작업 |
한편 파티션된 대용량 테이블에 split 함수를 실행하면 많은 시간이 걸린다. 이럴 때 exchange 기능을 이용하면 빠르고 안전하게 작업할 수 있다. <그림 4>에서 보는 것처럼 split를 해야 하는 파티션을 exchange에 의해 빈 공간으로 만든 다음 split을 하고 다시 데이터를 채우기 위해 split하는 것이다. 이렇게 하면 대용량의 데이터라도 매우 빠른 시간내에 split 작업을 수행할 수 있다.
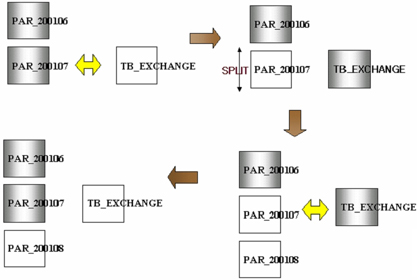 |
| <그림 4> 대용량 DB에서 split 작업 |
한편 대부분의 DBA들과 개발자들은 동일한 테이블을 생성할 때 create table ~ as select 구문을 이용한다. 대용량의 데이터일 경우 parallel 옵션을 줘 생성하기도 한다. 만약 1억 건의 테이블을 그대로 생성한다고 할 때 어떤 방법이 효과적일까. 이렇게 파티션된 대용량 테이블을 생성할 때는 exchange, program parallel 방법을 사용하는 것이 바람직하다.
 |
| <그림 5> 동일 테이블을 만들 때 |
<그림 5>는 이 과정을 도식화한 것이다. 먼저 생성할 TB_PART_1 테이블의 빈껍데기를 만든다. 대용량의 파티션된 테이블의 파티션 각각을 create table ~ as select 구문의 parallel 옵션을 이용해 각 테이블로 생성한다. 이후 미리 생성해 놓은 TB_PART_1 테이블의 파티션과 만들어 놓은 테이블들을 exchange하는 것이다. 이때 파티션별로 200105.sql, 200106.sql, 200107.sql…… 형식으로 만들어 놓고 이 프로그램들을 동시에 실행하면(program parallel) 극적인 효과를 볼 수 있다.
이번엔 데이터 마이그레이션에 대해 살펴 보자. 원격으로 데이터를 옮겨야 할 때 보통 database link를 이용한다. 네트워크를 통해 데이터를 옮기면 직렬(serial)로 데이터가 이동되므로 속도가 현저하게 떨어지기 때문이다. 따라서 소스 테이블을 파티셔닝하고 해당 파티션을 액세스하는 프로그램을 각각 띄워 병렬 프로세싱을 하게 되면 매우 빠른 속도로 데이터를 옮길 수 있다.
소스 테이블을 파티셔닝할 수 있는 상황이라면 테이블의 분포를 보고 레인지나 리스트 방식으로 파티셔닝할 수 있고, 일정한 분포가 존재하지 않는 테이블이라면 해시 파티셔닝으로 분포도를 고르게 나눈 다음 해당 파티션을 읽는 뷰를 액세스해 데이터를 옮기는 것이 좋다.
예를 들어 다음은 중대형 정도 크기인 약 2700만 건의 회원 테이블을 옮기는 DDL 스크립트다. 앞서 언급한 대로 이를 바로 database link를 이용해 처리하면 네트워크의 속도가 떨어져 엄청난 시간이 소요된다. 그러나 이것을 일반 테이블을 여러 개로 파티션을 나누어서 파티션과 병렬 처리하면 성능이 크게 향상된다. 작업 순서는 다음과 같다.
create table t_cust_hash
storage (initial 5M next 5M pctincrease 0)
partition by hash(mem_no)
(
partition par_hash_1 TABLESPACE TS_DATA,
partition par_hash_2 TABLESPACE TS_DATA,
partition par_hash_3 TABLESPACE TS_DATA,
partition par_hash_4 TABLESPACE TS_DATA,
partition par_hash_6 TABLESPACE TS_DATA,
partition par_hash_7 TABLESPACE TS_DATA,
partition par_hash_8 TABLESPACE TS_DATA,
partition par_hash_9 TABLESPACE TS_DATA,
partition par_hash_10 TABLESPACE TS_DATA,
)
nologging
as
select /*+ parallel(x 10) */ * from t_cust x
이제 다음과 같이 소스 테이블 뷰 생성한 후
create or replace view t_cust_1
as select * from t_cust_hash partition (par_hash_1);
create or replace view t_cust_2
as select * from t_cust_hash partition (par_hash_2);
create or replace view t_cust_3
as select * from t_cust_hash partition (par_hash_3)
……
다음과 같이 프로그램 패러럴(program parallel) 작업을 동시에 실행한다.
T_cust_1.sql
create table t_cust_1
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_1@remote x;
T_cust_2.sql
create table t_cust_2
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_2@remote x
이것은 단적인 예에 지나지 않는다. 활용할 수 있는 사례는 얼마든지 있을 것이다. 한편 인덱스는 전체 데이터에 대해 해당 컬럼의 값으로 정렬하기 때문에 대용량 테이블의 경우 create, rebuild 명령을 실행할 때 많은 시간이 필요하다. 이때 파티션된 인덱스를 만들면 인덱스의 생성과 관리를 더 활용적으로 할 수 있다. 다음은 파티션된 인덱스를 Unusable로 생성한 사례다(로컬/글로벌 파티션된 인덱스).
먼저 파티션 인덱스를 ‘unusable’ 옵션을 이용해 생성한다. 실제 데이터를 정렬해 만드는 것이 아니라 일종의 껍데기를 만드는 과정이다. 이제 앞서 살펴본 병렬 처리를 이용해 여러 파티션을 동시에 rebuild를 하면 대용량 데이터라도 빠른 시간에 인덱스를 생성할 수 있다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
UNUSABLE;
이제 파티션별로 index1.sql, index2.sql 등을 독립적으로 병렬 실행한다.
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_10 PARALLEL 4; ---‘ index1.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_20 PARALLEL 4; ---‘ index2.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_30 PARALLEL 4; ---‘ index3.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_40 PARALLEL 4; ---‘ index4.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_MAX PARALLEL 4; ---‘ index5.sql
지금까지 테이블 파티셔닝에 대해 다뤄봤다. 자동화된 성능관리 툴로 커버할 수 없는 영역을 살펴보고 있으나 가장 중요한 것은 데이터베이스 액세스 개념에 대해 정확하게 이해하는 것이다. 많은 사람들이 파티셔닝을 알고 있지만 정확하게 사용하고 있지 못하는 현실이 아타까울 때가 많다. 그러나 이 점은 역설적으로 파티셔닝의 매력이기도 하다. 노력하는 데이터베이스 관리자 만이 도전해 볼 수 있는 영역이 바로 ‘파티셔닝’ 분야이기 때문이다.@
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.
2011년 9월 4일 일요일
2011년 8월 30일 화요일
적절한 서버측 스크립트 언어 선택하기
http://www.ibm.com/developerworks/kr/library/l-script-survey/index.html

 평균 평가 등급 (총 2표)현재 여러분의 웹사이트가 동적인 컨텐츠를 제공하고 있다고 가정할 때, 여러분은 사용 가능한 수많은 오픈 소스 서버측 스크립트 언어들 중 어떤 기준으로 하나를 선택한 것인가? 상부의 지시에 따라 선택했는가? 아니면 방법론적인 측면에서 각각의 언어의 장단점, 사이트의 요구사항, 데드라인, 여러분 자신의 스킬 등을 따져서 가장 나은 것을 선택한 것인가? 그렇지 않다면 이 글을 읽기 바란다. 사용하기 쉽고, 더욱 강력하고, 유지관리가 쉽고, 재미있는 스크립팅 솔루션을 찾게 될 것이다.
평균 평가 등급 (총 2표)현재 여러분의 웹사이트가 동적인 컨텐츠를 제공하고 있다고 가정할 때, 여러분은 사용 가능한 수많은 오픈 소스 서버측 스크립트 언어들 중 어떤 기준으로 하나를 선택한 것인가? 상부의 지시에 따라 선택했는가? 아니면 방법론적인 측면에서 각각의 언어의 장단점, 사이트의 요구사항, 데드라인, 여러분 자신의 스킬 등을 따져서 가장 나은 것을 선택한 것인가? 그렇지 않다면 이 글을 읽기 바란다. 사용하기 쉽고, 더욱 강력하고, 유지관리가 쉽고, 재미있는 스크립팅 솔루션을 찾게 될 것이다.
개인적으로 Java 서블릿, Perl, PHP, Python, Tcl등 5개 언어 선택에 있어서 나는 매우 과학적인 개념을 사용한다. 두 가지 유형으로 이 언어들을 분류할 수 있다. Common Gateway Interface(HTML을 리턴하는 외부 프로그램을 호출)와 일명 슈퍼 마크업(다른 언어 마크업 코드를 포함하는 HTML 페이지, 즉 HTML의 슈퍼셋(superset))이라고 하는 것이다. 여러분이 선호하는 서버 스크립팅 툴을 누락시켰다면 이해해주길 바란다. 모든 컴파일 가능한 툴을 가지고 있지 않기 때문이다.
각 언어들의 작동방법을 나란히 보여주기 위해, 각각의 언어로 다음과 같은 동일한 여섯 가지 태스크를 구현하였다.
위의 기본 태스크를 위해서 각 언어 당 1 개씩, 모두 5개의 스크립트(참고자료)를 제공한다. 여기서 잠깐 시간을 내어 먼저 전반적으로 각 스크립트 언어를 검토한 후 상세한 분석에 들어 가도록 하겠다. 이 중 어떤 언어의 전문가가 이 코드를 본다면, 여기서 사용한 각 언어의 숙어가 매우 적음을 알게 될 것이다. 난 초보자의 편의를 위해 성능(performance)을 포기하고 가독성(readability)에만 신경을 썼다.
태스크별로 프로그램에 대해 상세히 알아보겠다.
태스크 1: time/date 불러오고 포맷하기
이것은 다른 어떤 언어보다도 스크립트 언어가 편리하다. 스크립트가 로그에 기록할 때 사람이 읽기 편한 포맷으로 time/date를 보여주길 원할 것이다. 이 기본 기능에 대한 두 가지 방법론적 입장(특히 Raw Date 와 Formatted Date)이 있다는 것은 매우 흥미로운 일이다.
Raw Date 방법은 Perl, Python, Tcl의 경우가 이에 포함되는데, 기준 시간 부터 초의 수를 리턴한 후 시간 및 날짜 포맷 함수를 거쳐 기술되는 방식이다. 날짜 데이터에 조작을 많이 가해야 하는 경우라면 Java 서블릿이나 PHP가 제공하는 완전히 포맷된 문자열로서의 날짜 데이터가 더 나을 것이다. 물론 예외 없는 규칙은 없으며 여기서 모든 것을 언급하지는 않겠다.
태스크2: 폼 필드의 데이터를 변수에 저장하기
각 언어는 환경에서 "name=value" 쌍을 불러오기 위해 자체 고유 방법과 숙어가 있다. 대부분 이 기본 트레이드 트릭은 각각 새로운 스크립트로 잘라서 붙여넣기의 단순한 방법이다. 또한 필요하면 수정도 하는데 많지는 않다. 웹 서버가 외부 프로그램을 호출할 경우는 클라이언트 브라우저에 의해 전송된 데이터는 그 프로그램 환경에 있는 특정 변수에 할당된다. 포스트 메소드를 사용하는 HTML 형식을 위해서 프로그램은 standard in(STDIN)에서 "Comment Length" 환경 변수에 있는 바이트 수를 읽어야 한다. STDIN에서 데이터를 보관하는 프로그램 변수는 지금 "name=value" 페어(pair) 문자열을 보관하고 URL 디코드 값, 단편으로 분리한 다음 프로세싱 변수로 입력할 필요가 있다.
다음이 그 예제이다(오류 검사가 없다는 것을 유의):
Python은 할당 변수 값에 직접 액세스를 허용하여 태스크를 단순화시키는 모듈을 사용한다 :
Python:
PPHP 및 Java 서블릿을 사용하는 경우 예상한 변수명을 받으면 첫번째 단계를 생략하고 바로 할당될 수 있다. 보다 더 일반적인 프로세스로 생성하여 처리하려면 접수된 변수 리스트 통해 프로세스를 반복하여 이 리스트를 동적 할당 시키는 것이 적합하다.
PHP:
Java:
Perl의 표준 코드 블록은 모듈에 숨겨지는 것이 아니다. 여기서 모든"name=value" 쌍은 문자열에서 발췌되어 각각 @pairs array에서 슬롯에 할당된다.
Perl:
그 다음, 배열을 통해 이름 및 값의 변수 입력을 반복한다 :
브라우저로 제출된 값은 서버로 전송하기 위해 "URL encoded"된 것이므로, 먼저 모든 +s를 공백으로 변경한 다음에 모든 escape 코드를 원래의 값으로 변환시켜 "URL encoded"된 값을 가져야 한다.
마지막으로 = (equal)의 우측에 있는 무엇이든지 = sign 좌측의 명명된 변수 값으로 할당한다.
Tcl 코드 방법도 이와 동일하다. 모든 프로그램에 이 논리를 적용시키게 되면 지루하면서 오류를 범할 수 있다. 다행히 어떤 CGI 프로그램에서 축어를 사용하여 이 블록을 잘라내어 붙여넣기(paste)할 수 있다.
태스크 3: 검색 및 대체
HTML 폼에 입력된 데이터는 빈번하게 수정이 필요하게 된다. 또한 사용자가 입력한 데이터를 이용하여 쉘 명령어를 실행하려면 절대적으로 필요 한 절차이다. 시스템의 무결성을 손상시키는 어떤 입력된 데이터라도 정리 작업이 필요하다.
Perl은 가장 강력한 정규식 엔진(regular expression engine)을 가지며 텍스트 조작에서 뛰어난 성능을 발휘한다. 여러분의 프로그램에 많은 텍스트 조작이 필요하다면 Perl을 사용하는 것이 좋을 것이다. Python, PHP, Tcl은 Perl의 화려한 구문(syntax)과 비교했을 때 각각의 인터페이스는 부자연스럽고 복잡해 보이긴 하나, 정규식의 검색 및 대체를 지원한다. 명확성을 위하여 각각 동일한 변수명 사용에 참조할 수 있는 수정된 스크립트 예제가 있다. 대소문자를 구별하지 않고 "cat"이라는 문자를 검색한 후 'data'변수의 값으로 할당한 후 다시 각각에 대해 "dog"단어로 대체된다 :
Perl:
PHP:
Python:
Tcl:
Java 언어는 정규식을 지원하지 않는다. 그러나 substring을 이용하여 쉽게 문자열 대체기능을 구현할 수 있다 :
Java:
별로 우아하게 보이지 않는다. 다른 언어로 같은 기능을 구현해보면 명확하고 간단 명료한 하나의 구문으로 표현할 수 있으므로 그것이 더 나아 보인다. 어쨌든 Sun은 표준 Java에 정규식 관련 기능을 넣지 않기로 결정했다.
태스크 4: 파일 쓰기
Java 서블릿을 제외한 나머지 언어의 경우 직관적이고 유사한 형태를 보인다. 각각의 언어에서 "file.txt"라는 파일을 추가(append) 모드로 여는 방법과 "out"이라는 변수에 파일 핸들로서 어떻게 할당하는지 비교해보라 :
Java:
Perl:
PHP:
Python:
Tcl:
PHP, Python, Tcl 코드의 단순성, 직관성 및 유사성을 주목하자. Perl 코드도 아주 비슷하면서 쉽고 직관적이다. Java에서의 "그것을 위한 클래스가 존재한다(There's a class for that)"라는 식의 접근법과 대조해 보라. 사실상 Java에는 이런 작업과 관련된 60개의 클래스가 존재한다. 언어 자체에서 알아서 수행하는 대신, 어떤 출력 스트림을 사용할 것인지, 그리고 모든 입출력 상황에서 어떤 특정한 프린트 라이터(print writer)를 사용할 것인지를 직접 결정해야 한다. 더구나 구문의 끝에 있는"true"가 추가 모드(append mode)의 의미로 받아들일 수 있을 만큼 직관적인가? PHP, Python, Tcl은 추가 모드의 경우 'a'를 사용한다. 그리고 파일 핸들링도 이해하기 쉬우며 몇 번의 타이핑으로 끝난다.
여기서 증명된 대로 파일 쓰기 태스크는 (파일 핸들 "out"에 변수 "joined"의 내용을 쓰는 것) 전체적으로 비슷하다 :
Java:
Perl:
PHP:
Python:
Tcl:
태스크 5: 파일 읽기
스크립트 언어에서 파일을 읽기 위해 여는 일은 매우 간단하지만, Java에서는 객체의 생성이 요구된다. 사실 파일 읽기는 각 언어마다 약간의 차이가 있고 언어 간의 원리적인 차이를 보여준다. Perl 및 Python은 각 행을 배열 또는 목록의 요소에 적절하게 할당하고 각 요소에 대해 이를 반복하여 처리함으로써 전체 파일 읽기를 용이하게 해준다. 다른 언어 툴은 한 개의 행을 읽고 이를 처리하고 나서 또 다른 행을 찾을 수 있게 되어 있다. 다음 사례는 가장 소수의 코드부터 최대수의 코드까지의 예이다. 각 사례에서 파일 핸들이 'in'이고 각 행은 STDOUT로 인쇄된다 :
Perl:
Note: Python 프로그래머들은 Perl은 추가적인 문자를 사용한다는 내용의 메일을 나에게 보내기 전에, "foreach" 대신 "for" 또는 아예 전체를 for (<IN>){ print }로 사용할 수도 있었다는 것을 알기 바란다.
Python:
PHP:
Tcl:
Java:
태스크 6: 콤마 구분 행(comma-delimited)을 변수로 분리
스트립트는 CSV 파일에서 행을 읽는다. 각 필드를 쉽게 개별 변수로(이 경우 a,b,c,d) 분리하는 방법은 무엇일까? Perl, PHP, Python은 구분자를 인수로 하여 문자열을 분리하는데 편리한 'split' 함수를 가지고 있다. Java 서블릿과 Tcl는 각 필드를 개별적으로 설정해야 한다. 이 예제에서는 문제가 없으나 각 행이 많은 필드를 가지는 경우에는 반드시 주의해야 한다.
Perl:
PHP:
Python:
Java:
Tcl:
데이터 손상 주의
모든 입력 자료가 손상될 가능성 있다고 가정하고 최악의 사태를 대비해야 한다. 시스템 명령어를 데이터에 입력하여 해커들이 시스템 침입할 수 있다. 예를 들면 서버 스트립팅을 통해 사용자가 시스템에서 원격 프로그램을 실행할 수 있다. 시스템 침입에 대해 설명하는 것은 절대 아니다. 디렉터리 리스트를 불러오기와 같은 단순한 요청에서 발생될 수 있다는 것이다.
사용자에게 디렉터리명으로 "~" 또는 ".."과 같은 예상되는 입력 나열을 요청할 수 있다. 그러면 이 요청은 "ls ~" 같은 ls 명령어와 함께 쉘로 전송된다. 악의는 없지만 해커가 만약 "~;rm *"을 입력한다면? 쉘은 먼저 "ls ~" 다음에 "rm *"을 실행하면서 기꺼이 명령을 실행할 것이다.
의도한 바가 아니라 해도 그러한 데이터 손상에 주의를 하지 않으면 충분히 가능성이 있는 일이다. 예를 들면, Perl에서 알파벳과 숫자 또는 언더라인/별표/틸드 이외의 모든 것을 아예 제거할 수도 있다. 그런 경우에는 "ls ~;rm *" 명령은 "ls ~rm *"이 된다. 입력을 잘못해도 시스템에 큰 손상을 입히는 것이 아니라 단순한 오류만을 발생시킬 뿐이다.
적절한 언어 선택하기
자, 이제 교체하여 사용할 만한, 또는 현재 사용하는 것에 만족을 느낄 수 있을 만한 최상의 언어는 어떤 것일까? 사용하기에 최상의 언어란 가장 친숙한 언어이다. 별로 소용없는 대답 또는 완전 초보자에게는 쓸모없는 잔소리처럼 들릴 수도 있다. 간단한 사실은 Perl을 모르는 Tcl의 베테랑이라 하더라도 "다른 모든 사람들이 Perl을 사용할 줄 안다"는 이유로 전체 사이트의 CGI를 Perl로 작성하지는 못한다는 것이다. 더구나 개발 시간 확장이 필요한 것 외에도 매우 현실적인 위험이 도사리고 있다(우연히 보안 허점을 남기는 것 등). 그러나 잘 모르는 언어라도 바꿀만한 충분한 이유가 있다면, 중대한 웹 애플리케이션을 곧바로 작성하지 말고, 이전에 써왔던 스크립트를 새로운 언어로 포팅하는 작업부터 권유하고 싶다.
한가지 짚고 넘어가고 싶은 것은, 일반적인 생각과는 달리 Java 서블릿이나 PHP가 다른 스크립트 언어들보다 별로 빠르지 않다는 것이다. 이 언어의 엔진은 웹 서버의 일부로서 실행된다. 따라서 CGI 스크립트에서처럼 리소스를 요청할 때마다 새로운 프로세스 시작을 요구하지는 않는다는, 즉 Java 서블릿과 PHP가 다른 스크립트 언어보다 속도가 빠르다는 주장이 가능한 것이다. 그러나 위의 비교는 프로그램을 "CGI 방식"으로만 실행하는, 즉 Perl, Python 또는 Tcl 엔진을 서버에 탑재하지 않을 경우에만 사실이다. 이 언어들의 사용자는 깊이 들여다 볼 필요가 있는 모듈들이 존재하기 때문이다.
CGI 게임을 처음 접하려는 사람이라면, 이 몇 가지의 가능성에 대해 호기심을 가질 수 있다. 처음에 어떤 언어를 선택할 지에 대해 모든 프로그램을 검토해 보고 가장 적당한 언어를 검토해 본다. 직관적 또는 콘텍스트에서 쉽게 진행상황을 파악할 수 있는가? 스크래치부터 구성까지의 시도에서 더욱 편안하게 느껴지는 것이 어떤 것인가? dream과 speech에서 눈에 거슬리는 것이 어떤 것인가? 모두 무료이기 때문에 비용은 논의 대상에서 제외한다. 시스템에 웹 서버를 탑재하고 시작하자.
마지막으로 내가 Java 서블릿을 server-side 솔루션으로 비난한 것처럼 느껴질 수 있는데 그럴 의도는 전혀 없다. 대부분 다른 언어로는 server-side 애플리케이션을 잘 만들지 않는다. 또한 Java의 객체 지향적 문법 및 패키징의 오버헤드는 항상 개발 시간 및 노력을 투자할 가치가 있는 것은 아니다. 기타 언어 보다 Java 서블릿을 사용하는 것은 다음과 같은 실질적인 두 가지 이유 때문이다. 첫째, 여러분 회사의 시스템이 Java기반으로 되어 있고 server-side 프로그램밍 하는데 Java 프로그래머가 필요한 경우이다. 둘째, 여러분의 server-side 프로그래밍이 대규모의 복잡한 프로그램이 요구됨에 따라 "Java의 힘"이 필요하다고 판단 될 경우이다. 아는 채만 할 줄 아는 여러분의 보스가 이 같은 사항을 결정한 것이라면, 다른 한 언어를 사용하여 구축하고, 몇 주 동안 인터넷 서핑을 즐기다가, Java로 완성한 것이라고 나중에 보고하라.
참고자료
5개 언어로 구성된 홈 페이지:
CGI 성능 향상:
필자소개
적절한 서버측 스크립트 언어 선택하기
동일한 기본적인 작업을 다섯 가지 언어가 구현하는 방법 요약: Perl, PHP, Python, Tcl 및 Java 서블릿과 같은 인기 있는 다섯 가지 스크립트 툴(script tools)을 동일한 6개의 일반적인 서버 사이드(sever-side) 태스크에 적용시켜 비교해 본다. 각각의 문법(syntax)을 나란히 조사하고 어떻게 각 언어가 특정한 태스크를 처리하는지에 대해 평가 할 수 있다. 서버측 스크립트 언어를 사용해본 적이 없거나 이들 언어 중 일부만 사용해 보았다면 이들 언어들이 어떻게 닮았는지 확인할 수 있을 것이다. 이미 한 언어에 익숙해 있다고 하더라도 가용성, 기능성, 그리고 가독성에 있어서 다른 언어들이 어떤 특징을 갖는지 파악할 수 있을 것이다.
개인적으로 Java 서블릿, Perl, PHP, Python, Tcl등 5개 언어 선택에 있어서 나는 매우 과학적인 개념을 사용한다. 두 가지 유형으로 이 언어들을 분류할 수 있다. Common Gateway Interface(HTML을 리턴하는 외부 프로그램을 호출)와 일명 슈퍼 마크업(다른 언어 마크업 코드를 포함하는 HTML 페이지, 즉 HTML의 슈퍼셋(superset))이라고 하는 것이다. 여러분이 선호하는 서버 스크립팅 툴을 누락시켰다면 이해해주길 바란다. 모든 컴파일 가능한 툴을 가지고 있지 않기 때문이다.
각 언어들의 작동방법을 나란히 보여주기 위해, 각각의 언어로 다음과 같은 동일한 여섯 가지 태스크를 구현하였다.
- 태스크 1 : time/date 가져오고 포맷하기
- 태스크 2: 폼 필드의 데이터를 변수에 저장하기: 2개의 HTML 폼 필드
- 태스크 3: 검색 및 대체
- 태스크 4: 파일 쓰기: 트랜잭션 날짜 및 시간에 따라 컴마로 분리된 두개의 값을 CSV 텍스트 파일(CSV = comma-separated values, 예: 1,2,3)에 기록
- 태스크 5: 파일 읽기: 모든 CSV 파일의 기록을 읽고 표시한다.
- 태스크 6: 행을 컴마로 구분하여 변수에 할당: 앞의 파일의 내용을 컴마로 구분하여 다시 변수에 할당한다.
위의 기본 태스크를 위해서 각 언어 당 1 개씩, 모두 5개의 스크립트(참고자료)를 제공한다. 여기서 잠깐 시간을 내어 먼저 전반적으로 각 스크립트 언어를 검토한 후 상세한 분석에 들어 가도록 하겠다. 이 중 어떤 언어의 전문가가 이 코드를 본다면, 여기서 사용한 각 언어의 숙어가 매우 적음을 알게 될 것이다. 난 초보자의 편의를 위해 성능(performance)을 포기하고 가독성(readability)에만 신경을 썼다.
태스크별로 프로그램에 대해 상세히 알아보겠다.
태스크 1: time/date 불러오고 포맷하기
이것은 다른 어떤 언어보다도 스크립트 언어가 편리하다. 스크립트가 로그에 기록할 때 사람이 읽기 편한 포맷으로 time/date를 보여주길 원할 것이다. 이 기본 기능에 대한 두 가지 방법론적 입장(특히 Raw Date 와 Formatted Date)이 있다는 것은 매우 흥미로운 일이다.
Raw Date 방법은 Perl, Python, Tcl의 경우가 이에 포함되는데, 기준 시간 부터 초의 수를 리턴한 후 시간 및 날짜 포맷 함수를 거쳐 기술되는 방식이다. 날짜 데이터에 조작을 많이 가해야 하는 경우라면 Java 서블릿이나 PHP가 제공하는 완전히 포맷된 문자열로서의 날짜 데이터가 더 나을 것이다. 물론 예외 없는 규칙은 없으며 여기서 모든 것을 언급하지는 않겠다.
태스크2: 폼 필드의 데이터를 변수에 저장하기
각 언어는 환경에서 "name=value" 쌍을 불러오기 위해 자체 고유 방법과 숙어가 있다. 대부분 이 기본 트레이드 트릭은 각각 새로운 스크립트로 잘라서 붙여넣기의 단순한 방법이다. 또한 필요하면 수정도 하는데 많지는 않다. 웹 서버가 외부 프로그램을 호출할 경우는 클라이언트 브라우저에 의해 전송된 데이터는 그 프로그램 환경에 있는 특정 변수에 할당된다. 포스트 메소드를 사용하는 HTML 형식을 위해서 프로그램은 standard in(STDIN)에서 "Comment Length" 환경 변수에 있는 바이트 수를 읽어야 한다. STDIN에서 데이터를 보관하는 프로그램 변수는 지금 "name=value" 페어(pair) 문자열을 보관하고 URL 디코드 값, 단편으로 분리한 다음 프로세싱 변수로 입력할 필요가 있다.
다음이 그 예제이다(오류 검사가 없다는 것을 유의):
Python은 할당 변수 값에 직접 액세스를 허용하여 태스크를 단순화시키는 모듈을 사용한다 :
Python:
form = cgi.FieldStorage() data = form['data'].value data2 = form['data2'].value |
PPHP 및 Java 서블릿을 사용하는 경우 예상한 변수명을 받으면 첫번째 단계를 생략하고 바로 할당될 수 있다. 보다 더 일반적인 프로세스로 생성하여 처리하려면 접수된 변수 리스트 통해 프로세스를 반복하여 이 리스트를 동적 할당 시키는 것이 적합하다.
PHP:
$data = $HTTP_POST_VARS["data"]; $data2 = $HTTP_POST_VARS["data2"]; |
Java:
String data = request.getParameter("data");
String data2 = request.getParameter("data2");
|
Perl의 표준 코드 블록은 모듈에 숨겨지는 것이 아니다. 여기서 모든"name=value" 쌍은 문자열에서 발췌되어 각각 @pairs array에서 슬롯에 할당된다.
Perl:
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
@pairs = split(/&/, $buffer);
|
그 다음, 배열을 통해 이름 및 값의 변수 입력을 반복한다 :
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair); |
브라우저로 제출된 값은 서버로 전송하기 위해 "URL encoded"된 것이므로, 먼저 모든 +s를 공백으로 변경한 다음에 모든 escape 코드를 원래의 값으로 변환시켜 "URL encoded"된 값을 가져야 한다.
$name =~ tr/+/ /;
$name =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
$value =~ tr/+/ /;
$value =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg; |
마지막으로 = (equal)의 우측에 있는 무엇이든지 = sign 좌측의 명명된 변수 값으로 할당한다.
$Form{$name} = $value;
} |
Tcl 코드 방법도 이와 동일하다. 모든 프로그램에 이 논리를 적용시키게 되면 지루하면서 오류를 범할 수 있다. 다행히 어떤 CGI 프로그램에서 축어를 사용하여 이 블록을 잘라내어 붙여넣기(paste)할 수 있다.
태스크 3: 검색 및 대체
HTML 폼에 입력된 데이터는 빈번하게 수정이 필요하게 된다. 또한 사용자가 입력한 데이터를 이용하여 쉘 명령어를 실행하려면 절대적으로 필요 한 절차이다. 시스템의 무결성을 손상시키는 어떤 입력된 데이터라도 정리 작업이 필요하다.
Perl은 가장 강력한 정규식 엔진(regular expression engine)을 가지며 텍스트 조작에서 뛰어난 성능을 발휘한다. 여러분의 프로그램에 많은 텍스트 조작이 필요하다면 Perl을 사용하는 것이 좋을 것이다. Python, PHP, Tcl은 Perl의 화려한 구문(syntax)과 비교했을 때 각각의 인터페이스는 부자연스럽고 복잡해 보이긴 하나, 정규식의 검색 및 대체를 지원한다. 명확성을 위하여 각각 동일한 변수명 사용에 참조할 수 있는 수정된 스크립트 예제가 있다. 대소문자를 구별하지 않고 "cat"이라는 문자를 검색한 후 'data'변수의 값으로 할당한 후 다시 각각에 대해 "dog"단어로 대체된다 :
Perl:
$data =~ s/cat/dog/gi; } |
PHP:
$data = eregi_replace("cat","dog",$data);
} |
Python:
data = regsub.gsub("cat", "dog", data)
} |
Tcl:
regsub -all -nocase {cat} $data {dog} data
} |
Java 언어는 정규식을 지원하지 않는다. 그러나 substring을 이용하여 쉽게 문자열 대체기능을 구현할 수 있다 :
Java:
String findString = new String("cat");
String replaceString = new String("dog");
int x = data.indexOf(findString);
while(x != -1)
{
data = new String(data.substring(0,x)
+ replaceString
+ data.substring(x+findString.length()));
x = sourceString.indexOf(findString);
}
|
별로 우아하게 보이지 않는다. 다른 언어로 같은 기능을 구현해보면 명확하고 간단 명료한 하나의 구문으로 표현할 수 있으므로 그것이 더 나아 보인다. 어쨌든 Sun은 표준 Java에 정규식 관련 기능을 넣지 않기로 결정했다.
태스크 4: 파일 쓰기
Java 서블릿을 제외한 나머지 언어의 경우 직관적이고 유사한 형태를 보인다. 각각의 언어에서 "file.txt"라는 파일을 추가(append) 모드로 여는 방법과 "out"이라는 변수에 파일 핸들로서 어떻게 할당하는지 비교해보라 :
Java:
PrintWriter out = new PrintWriter(new FileOutputStream("file.txt",true));
|
Perl:
open (OUT, ">>file.txt"); |
PHP:
$out = fopen("file.txt", "a");
|
Python:
out = open("file.txt", 'a')
|
Tcl:
set out [open "file.txt" a+] |
PHP, Python, Tcl 코드의 단순성, 직관성 및 유사성을 주목하자. Perl 코드도 아주 비슷하면서 쉽고 직관적이다. Java에서의 "그것을 위한 클래스가 존재한다(There's a class for that)"라는 식의 접근법과 대조해 보라. 사실상 Java에는 이런 작업과 관련된 60개의 클래스가 존재한다. 언어 자체에서 알아서 수행하는 대신, 어떤 출력 스트림을 사용할 것인지, 그리고 모든 입출력 상황에서 어떤 특정한 프린트 라이터(print writer)를 사용할 것인지를 직접 결정해야 한다. 더구나 구문의 끝에 있는"true"가 추가 모드(append mode)의 의미로 받아들일 수 있을 만큼 직관적인가? PHP, Python, Tcl은 추가 모드의 경우 'a'를 사용한다. 그리고 파일 핸들링도 이해하기 쉬우며 몇 번의 타이핑으로 끝난다.
여기서 증명된 대로 파일 쓰기 태스크는 (파일 핸들 "out"에 변수 "joined"의 내용을 쓰는 것) 전체적으로 비슷하다 :
Java:
out.println(joined); |
Perl:
print OUT "$joined\n"; |
PHP:
fwrite($out, $joined); |
Python:
out.write (joined) |
Tcl:
puts $out $joined |
태스크 5: 파일 읽기
스크립트 언어에서 파일을 읽기 위해 여는 일은 매우 간단하지만, Java에서는 객체의 생성이 요구된다. 사실 파일 읽기는 각 언어마다 약간의 차이가 있고 언어 간의 원리적인 차이를 보여준다. Perl 및 Python은 각 행을 배열 또는 목록의 요소에 적절하게 할당하고 각 요소에 대해 이를 반복하여 처리함으로써 전체 파일 읽기를 용이하게 해준다. 다른 언어 툴은 한 개의 행을 읽고 이를 처리하고 나서 또 다른 행을 찾을 수 있게 되어 있다. 다음 사례는 가장 소수의 코드부터 최대수의 코드까지의 예이다. 각 사례에서 파일 핸들이 'in'이고 각 행은 STDOUT로 인쇄된다 :
Perl:
@lines = <IN>;
foreach $line (@lines){
print $line;
}
|
Note: Python 프로그래머들은 Perl은 추가적인 문자를 사용한다는 내용의 메일을 나에게 보내기 전에, "foreach" 대신 "for" 또는 아예 전체를 for (<IN>){ print }로 사용할 수도 있었다는 것을 알기 바란다.
Python:
lines = in.readlines()
for line in lines:
print line
|
PHP:
while (!feof($in)) {
$line = fgets($in, 4096);
print $line;
}
|
Tcl:
while {1} {
gets $in line
puts $line
if {$line == ""} {
break
}
}
|
Java:
do {
try {
line = in.readLine();
if (line != null){
out.println(line);
}
}
catch(Exception e) {
e.printStackTrace();
}
}
|
태스크 6: 콤마 구분 행(comma-delimited)을 변수로 분리
스트립트는 CSV 파일에서 행을 읽는다. 각 필드를 쉽게 개별 변수로(이 경우 a,b,c,d) 분리하는 방법은 무엇일까? Perl, PHP, Python은 구분자를 인수로 하여 문자열을 분리하는데 편리한 'split' 함수를 가지고 있다. Java 서블릿과 Tcl는 각 필드를 개별적으로 설정해야 한다. 이 예제에서는 문제가 없으나 각 행이 많은 필드를 가지는 경우에는 반드시 주의해야 한다.
Perl:
($a,$b,$c,$d) = split /,/, $lines[@lines-1]; |
PHP:
list( $a,$b,$c,$d ) = split( ",", $last, 4 ); |
Python:
a,b,c,d = splitfields(lines[-1], ',') |
Java:
String a, b, c, d;
StringTokenizer st = new StringTokenizer(last, ",");
a = st.nextToken();
b = st.nextToken();
c = st.nextToken();
d = st.nextToken();
|
Tcl:
set fieldlist [split $last ,]
set a [lindex $fieldlist 0]
set b [lindex $fieldlist 1]
set c [lindex $fieldlist 2]
set d [lindex $fieldlist 3]
|
데이터 손상 주의
모든 입력 자료가 손상될 가능성 있다고 가정하고 최악의 사태를 대비해야 한다. 시스템 명령어를 데이터에 입력하여 해커들이 시스템 침입할 수 있다. 예를 들면 서버 스트립팅을 통해 사용자가 시스템에서 원격 프로그램을 실행할 수 있다. 시스템 침입에 대해 설명하는 것은 절대 아니다. 디렉터리 리스트를 불러오기와 같은 단순한 요청에서 발생될 수 있다는 것이다.
사용자에게 디렉터리명으로 "~" 또는 ".."과 같은 예상되는 입력 나열을 요청할 수 있다. 그러면 이 요청은 "ls ~" 같은 ls 명령어와 함께 쉘로 전송된다. 악의는 없지만 해커가 만약 "~;rm *"을 입력한다면? 쉘은 먼저 "ls ~" 다음에 "rm *"을 실행하면서 기꺼이 명령을 실행할 것이다.
의도한 바가 아니라 해도 그러한 데이터 손상에 주의를 하지 않으면 충분히 가능성이 있는 일이다. 예를 들면, Perl에서 알파벳과 숫자 또는 언더라인/별표/틸드 이외의 모든 것을 아예 제거할 수도 있다. 그런 경우에는 "ls ~;rm *" 명령은 "ls ~rm *"이 된다. 입력을 잘못해도 시스템에 큰 손상을 입히는 것이 아니라 단순한 오류만을 발생시킬 뿐이다.
적절한 언어 선택하기
자, 이제 교체하여 사용할 만한, 또는 현재 사용하는 것에 만족을 느낄 수 있을 만한 최상의 언어는 어떤 것일까? 사용하기에 최상의 언어란 가장 친숙한 언어이다. 별로 소용없는 대답 또는 완전 초보자에게는 쓸모없는 잔소리처럼 들릴 수도 있다. 간단한 사실은 Perl을 모르는 Tcl의 베테랑이라 하더라도 "다른 모든 사람들이 Perl을 사용할 줄 안다"는 이유로 전체 사이트의 CGI를 Perl로 작성하지는 못한다는 것이다. 더구나 개발 시간 확장이 필요한 것 외에도 매우 현실적인 위험이 도사리고 있다(우연히 보안 허점을 남기는 것 등). 그러나 잘 모르는 언어라도 바꿀만한 충분한 이유가 있다면, 중대한 웹 애플리케이션을 곧바로 작성하지 말고, 이전에 써왔던 스크립트를 새로운 언어로 포팅하는 작업부터 권유하고 싶다.
한가지 짚고 넘어가고 싶은 것은, 일반적인 생각과는 달리 Java 서블릿이나 PHP가 다른 스크립트 언어들보다 별로 빠르지 않다는 것이다. 이 언어의 엔진은 웹 서버의 일부로서 실행된다. 따라서 CGI 스크립트에서처럼 리소스를 요청할 때마다 새로운 프로세스 시작을 요구하지는 않는다는, 즉 Java 서블릿과 PHP가 다른 스크립트 언어보다 속도가 빠르다는 주장이 가능한 것이다. 그러나 위의 비교는 프로그램을 "CGI 방식"으로만 실행하는, 즉 Perl, Python 또는 Tcl 엔진을 서버에 탑재하지 않을 경우에만 사실이다. 이 언어들의 사용자는 깊이 들여다 볼 필요가 있는 모듈들이 존재하기 때문이다.
CGI 게임을 처음 접하려는 사람이라면, 이 몇 가지의 가능성에 대해 호기심을 가질 수 있다. 처음에 어떤 언어를 선택할 지에 대해 모든 프로그램을 검토해 보고 가장 적당한 언어를 검토해 본다. 직관적 또는 콘텍스트에서 쉽게 진행상황을 파악할 수 있는가? 스크래치부터 구성까지의 시도에서 더욱 편안하게 느껴지는 것이 어떤 것인가? dream과 speech에서 눈에 거슬리는 것이 어떤 것인가? 모두 무료이기 때문에 비용은 논의 대상에서 제외한다. 시스템에 웹 서버를 탑재하고 시작하자.
마지막으로 내가 Java 서블릿을 server-side 솔루션으로 비난한 것처럼 느껴질 수 있는데 그럴 의도는 전혀 없다. 대부분 다른 언어로는 server-side 애플리케이션을 잘 만들지 않는다. 또한 Java의 객체 지향적 문법 및 패키징의 오버헤드는 항상 개발 시간 및 노력을 투자할 가치가 있는 것은 아니다. 기타 언어 보다 Java 서블릿을 사용하는 것은 다음과 같은 실질적인 두 가지 이유 때문이다. 첫째, 여러분 회사의 시스템이 Java기반으로 되어 있고 server-side 프로그램밍 하는데 Java 프로그래머가 필요한 경우이다. 둘째, 여러분의 server-side 프로그래밍이 대규모의 복잡한 프로그램이 요구됨에 따라 "Java의 힘"이 필요하다고 판단 될 경우이다. 아는 채만 할 줄 아는 여러분의 보스가 이 같은 사항을 결정한 것이라면, 다른 한 언어를 사용하여 구축하고, 몇 주 동안 인터넷 서핑을 즐기다가, Java로 완성한 것이라고 나중에 보고하라.
참고자료
5개 언어로 구성된 홈 페이지:
CGI 성능 향상:
필자소개
UNIX 네트워크 분석
http://www.ibm.com/developerworks/kr/library/tutorial/au-unixnetworkanalysis/index.html
http://www.ibm.com/developerworks/kr/library/tutorial/au-unixnetworkanalysis/section2.html
평균 평가 등급 (총 3표)시작하기 전에
이 튜토리얼은 다양한 장치에서 실행되고 있는 서비스 및 시스템을 포함한 네트워크 구조 및 구성에 대한 정보를 효율적으로 검색 및 확인할 수 있는 방법을 찾고 있는 UNIX 시스템 관리자를 대상으로 한다. 이 튜토리얼을 이해하려면 UNIX 운영 체제, 네트워크 및 IP(Internet protocol)의 작동 방법에 대한 기본 지식이 있어야 한다.
이 튜토리얼의 정보
새 UNIX 시스템뿐 아니라 기존 UNIX 시스템의 복잡한 작동 방법을 이해하는 데 있어서 핵심이 되는 부분은 네트워크 구성이다. 문제점을 올바르게 식별하고 잠재적인 문제점을 예방하기 위해서는 네트워크의 여러 가지 특성을 숙지하고 있어야 한다. 몇 가지 기본적인 도구와 명령을 사용하여 단일 시스템의 구성에 대한 여러 가지 정보를 확인할 수 있으며, 이 기본적인 이해를 바탕으로 네트워크의 나머지 부분에 대한 구성도 이해할 수 있다. 또한 몇 가지 추가 도구를 사용하여 네트워크 내의 추가 시스템 및 서비스에 대한 정보를 확인함으로써 이해의 지평을 넓힐 수 있다.
이 튜토리얼에서는 UNIX 환경 내에서 몇 가지 기본 도구를 사용하여 시스템의 구성 정보를 확인한다. 이러한 도구와 출력되는 정보를 이해하게 되면 시스템 네트워크 구성과 네트워크의 작동 방법에 이해의 깊이도 깊어질 것이다. 또한 더 넓은 네트워크를 검색하여 네트워크의 세부 정보, 잠재적 보안 문제 및 문제가 발생했을 때 문제점을 식별 및 진단하는 데 도움이 되는 주요 정보를 제공할 수 있는 도구 및 솔루션에 대해서도 살펴본다.
호스트의 네트워크 이해
네트워크를 이해하는 과정의 첫 번째 단계는 현재 사용 중인 시스템의 네트워크 구성을 이해하는 것이다. 이 단계에서는 현재 호스트의 IP 주소, DNS 구성 및 현재 호스트에서 연결하여 통신할 수 있는 시스템 등에 대한 여러 가지 기본적인 정보를 확인하게 된다.
구성 정보 찾기
작업 중인 시스템의 현재 구성을 보면 사용자의 환경에 대한 기본 정보를 파악할 수 있다. 우선 현재 시스템의 IP 주소와 네트워크 마스크를 확인할 수 있다. 이러한 두 값이 있으면 현재 시스템의 주소뿐만 아니라 현재 시스템에서 직접(예를 들어, 라우터를 사용하지 않고) 연결할 수 있는 네트워크 상의 다른 시스템을 확인할 수 있다.
IP 주소를 확인하기 전에 hostname 명령을 사용하여 시스템의 호스트 이름을 가져온다(Listing 1 참조).
Listing 1. 호스트 이름 가져오기
Listing 2. Solaris에서 실행한 ipconfig의 출력
이 출력을 보면 루프백 장치인 lo0이 있고, 이 장치의 주소가 로컬 호스트의 일반적인 주소인 127.0.0.1이라는 것을 알 수 있다. 또한 이 장치에 동등한 IPv6 주소도 있다는 것을 알 수 있다.
pcn0 장치는 네트워크 주소 192.168.1.25와 네트워크 마스크 fffffc00(255.255.252.0에 해당)으로 구성되어 있다. 또한 이 장치의 주소는 DHCP를 사용하여 설정되었다는 것을 알 수 있다(DHCP 플래그 목록 참조).
특히 네트워크 마스크가 중요하다. 왜냐하면 네트워크 마스크만 있으면 사용자가 직접 연결되어 있는 네트워크의 크기(등록된 IP 주소의 관점에서)를 확인할 수 있기 때문이다. 이 장치의 네트워크 마스크인 255.255.252.0은 클래스 C 주소가 4개임을 나타낸다(256(최대 호스트 수) - 252(마스킹된 호스트 수) = 4).
네트워크 마스크와 구성된 IP 주소를 결합하여 로컬 네트워크에 있는 IP 주소의 범위를 추측할 수 있다. 일반적으로 IP 블록은 전체 그룹별로 차례대로 분할되기 때문에 이 네트워크의 IP 주소 범위는 192.168.0.0부터 192.168.3.255까지이다. 4개의 클래스 C 주소로 구성된 네트워크 마스크를 사용하면 일반적으로 전체 범위(192.168.0.0-192.168.255.255)가 동일한 블록들로 분할되므로 주소 접두어가 192.168.1.x인 주소는 4개의 주소 블록 중 첫 번째 블록에 있다.
이 정보(및 세부 사항)는 운영 체제마다 각기 다른 방식으로 표시된다. Listing 3에서는 Linux® 시스템의 출력을 보여 준다.
Listing 3. Linux 시스템의 출력
Listing 4에서는 Mac OS X™ 시스템의 출력을 보여 준다.
Listing 4. Mac OS X 시스템의 출력
일반적으로 모든 운영 체제의 출력에서 연결된 네트워크 장치의 인터넷 주소와 네트워크 마스크를 볼 수 있다. 여러 개의 네트워크 장치가 있는 경우에는 각 장치에 대한 정보가 출력에 표시되며 사용자는 단 하나의 시스템에서 폭넓은 범위의 다양한 네트워크 및 시스템에 연결할 수 있다.
이름 확인 서비스 찾기
현재 시스템의 구성을 확인하는 과정의 다음 단계는 다른 시스템의 서비스에 액세스할 때 사용자의 시스템 이름 및 도메인 이름을 IP 주소로 변환하는 이름 서비스 시스템의 구성과 관련된다.
대부분의 시스템에서 이 구성은 /etc/nsswitch.conf 파일을 통해 설정하며, 이 파일에는 다양한 이름 서비스(호스트, 사용자 등)의 목록과 이름 확인에 사용할 다양한 서비스(DNS, NIS 또는 로컬 파일)의 순서가 들어 있다. Listing 5에서 이 파일의 예를 볼 수 있다.
Listing 5. 이름 서비스 시스템 확인하기
예를 들어, Listing 5에서 호스트 이름 정보는 시스템에 있는 로컬 파일(예: /etc/hosts)과 DNS(Domain Name System)를 차례대로 검색하여 확인한다.
DNS가 구성되어 있는 경우에는 /etc/resolv.conf 파일에서 이름을 IP 주소로 변환하는 데 사용 중인 시스템을 확인할 수 있다. Listing 6에서는 이 파일의 예제를 보여 준다.
Listing 6. 이름을 IP 주소로 변환하는 데 사용 중인 시스템
이 정보는 해당 시스템의 정보를 직접 쿼리하려는 경우에 유용하게 사용할 수 있다. dig 및 nslookup과 같은 도구를 사용하여 이름 및 IP 주소의 이름 서비스 및 확인에 대한 정보를 추출할 수 있다.
경로 검사하기
네트워크의 외부에 있는(즉, 현재 IP 주소와 비교하여 네트워크 마스크의 범위에서 벗어난) 호스트는 다른 시스템으로 전달되기 위해 라우터로 전송된다. 라우터는 부서 간, 다양한 물리적 사이트 및 인터넷과 같은 공용 외부 사이트를 포함한 네트워크의 모든 레벨에서 사용할 수 있다.
사용자의 시스템에서 '로컬' 네트워크의 외부에 있는 시스템과 통신하려는 경우 netstat 명령을 사용하여 연결된 시스템 또는 라우터를 구별할 수 있다. 예를 들어, 아래 Listing 7에서는 Solaris 시스템에서 실행한 netstat 명령의 출력을 보여 준다.
Listing 7. netstat 명령
기본 경로는 현재 네트워크의 외부에 있거나 특정 IP 주소 또는 IP 주소 범위의 다른 경로에서 아직 처리되지 않은 패킷을 라우팅하는 데 사용되는 게이트웨이(라우터)를 보여 준다.
현재 이름 서비스가 작동되지 않거나 올바른 정보를 리턴하지 않는 경우에는 이 정보를 확인할 필요가 있으며 -n 옵션을 지정하여 이름 대신 IP 주소를 사용하여 이 정보를 표시할 수 있다.
지원되는 서비스 검사하기
netstat 명령은 현재 호스트에서 공유 또는 노출하고 있는 서비스를 확인할 때도 사용할 수 있다. 이러한 서비스에는 DNS, NFS, 웹 서비스 및 기타 정보를 포함한 모든 네트워크 서비스가 포함된다. 표시된 정보는 클라이언트 연결을 대기하기 위해 '수신 중' 상태로 열려 있는 포트 또는 이미 열려 있는 상태에서 클라이언트와 통신 중인 포트를 기반으로 한다.
이 정보를 통해 서비스가 실행 중인지 여부를 확인할 수 있을 뿐 아니라 표준 보안 검사의 일환으로 시스템이 공유되고 있거나 필요 이상의 위험에 노출되어 있는지 여부를 확인할 수 있다.
Listing 8에서는 이 명령의 출력 예제를 볼 수 있다. 이 예제에서는
Listing 8.
이 출력에서 볼 수 있듯이 이 시스템에서는 매우 많은 작업이 수행되고 있다. 세 번째 열은 열려 있거나 수신 중인 각 연결에 대한 호스트 이름과 포트(콜론으로 구분)를 보여 준다. TCP 또는 UDP 서비스 번호가 알려진 포트 번호(/etc/services 파일 내에 정의된 포트 번호)와 일치하면 해당 서비스 이름이 출력에 표시된다. 호스트의 경우 호스트 이름, 대체 IP 주소 또는 '*' 기호가 표시된다. 별표는 해당 서비스 및 포트가 모든 IP 주소에서 열려 있고 수신 중임을 나타낸다.
예를 들어, Listing 9의 출력에서 시스템이 NFS를 지원하도록 구성되어 있고 열린(설정된) 연결이 있음을 알 수 있다.
Listing 9. NFS를 지원하도록 구성된 시스템
또한 이 출력에서는 현재 시스템과 통신 중인 시스템을 확인할 수도 있다. 예를 들어, 다섯 번째 열을 정렬한 다음 목록에서 중복된 항목을 제거하여 현재 시스템에 연결된 시스템 목록을 추출할 수 있다(Lisiting 10 참조).
Listing 10. 연결된 시스템 목록 추출하기
이 기능은 인식하지 못하고 있거나 원하지 않는 사용자 또는 컴퓨터가 현재 시스템에 연결되어 있는지 확인할 때 유용하게 사용할 수 있다.
이러한 다른 시스템에 대한 정보를 확인하려면 먼저 사용자의 네트워크에 있는 다른 컴퓨터를 검색해야 한다.
다른 호스트에 대한 정보 찾기
이제 로컬 시스템에 대한 기본 정보를 알고 있으므로 이제 네트워크의 다른 시스템도 검색하여 사용 가능한 시스템과 각 시스템에서 제공하는 서비스를 확인할 수 있다. 올바른 도구를 사용하여 이러한 시스템에서 실행 중인 운영 체제와 공유하고 있는 서비스까지도 확인할 수 있다.
호스트 검사하기
원격 시스템을 가장 쉽고 명확하게 검사하는 방법은 ping 도구를 사용하여 특정 호스트가 실행 중이고 사용 가능한지 여부를 검사하는 것이다. 매우 단순한 작업을 수행하는 ping 도구는 응답을 요청하는 원격 호스트에 패킷을 보낸 후 응답이 수신되면 시간 차이를 계산한다. 이렇게 패킷을 보내고 받는데 걸린 시간을 사용하여 현재 시스템과 대상 시스템의 거리를 표시할 수 있다.
예를 들어, 사용자의 네트워크에 있는 시스템에 대해 ping을 실행할 경우에는 ping 패킷에 대한 응답이 매우 빠르게 수신된다(Listing 11 참조).
Listing 11. 사용자의 네트워크에 있는 시스템에 대해 ping 실행하기
ping 도구는 구현 형태에 따라 각기 다른 방식으로 작동한다. Linux 및 Mac OS X의 경우 이 도구는 기본적으로 패킷을 지속적으로 보내면서 사용자가 Ctrl-C를 눌러서 애플리케이션을 종료할 때까지 응답을 기다린다.
Solaris™, AIX® 및 일부 기타 UNIX 운영 체제에서는 추가 인수 없이 ping 도구를 실행하면 원격 호스트가 응답했는지 여부만 표시된다(Listing 12 참조).
Listing 12. 기타 UNIX 운영 체제에서 추가 인수 없이 ping 실행하기
더 긴 테스트를 수행하려면 Listing 13과 같이
Listing 13.
각 행의 time 필드에는 각 패킷에 대한 속도와 지연 시간(응답이 수신되기 전까지의 지연 시간 및 활동 레벨을 나타내기도 함)이 표시된다. 출력을 중지하면 보내고 받은 패킷의 수와 시간 통계에 대한 요약 정보가 표시된다.
ping 패킷이 이동해야 하는 거리가 멀수록 원격 호스트의 응답 시간이 길어집니다. 예를 들어, 인터넷에 있는 공용 서버에 대해 ping을 실행할 경우에는 응답 패킷을 수신하는 데 걸린 시간이 상당히 커집니다(Listing 14 참조).
Listing 14. 인터넷에 있는 공용 서버에 대해 ping 실행하기
인터넷 서비스에 연결하는 데 걸린 시간(193ms)과 로컬 호스트에 연결하는 데 걸린 시간(0.23ms)을 비교해 보자.
ping 도구를 사용하면 연결하려는 원격 호스트에 도달할 수 있는지 여부도 빠르게 확인할 수 있다. 존재하지 않는 호스트에 대해 ping을 실행하면 특정 오류가 리턴된다(Listing 15 참조).
Listing 15. 존재하지 않는 호스트에 대해 ping 실행하기
ping 도구를 사용하려면 네트워크에 있는 다른 시스템에 대한 정보를 알아야 한다. 이제 이름이나 IP 주소를 사용하지 않고 네트워크에 있는 호스트를 확인하는 방법을 살펴보자.
네트워크에 있는 호스트 검색하기
이더넷 네트워크 시스템(및 기타 시스템) 내에서 네트워크의 모든 장치는 하드웨어 네트워크 장치와 연관된 고유 주소를 가지고 있다. MAC(Media Access Control) 번호는 네트워크 장치를 고유하게 식별하며 IP(Internet Protocol)와 같은 상위 레벨 프로토콜을 사용하여 MAC 주소와 호스트 이름을 연관시킬 수 있다.
MAC 주소는 운영 체제에서 패킷을 네트워크의 외부로 보낼 때(및 그 반대의 경우에) 사용된다. 패킷을 특정 호스트 이름으로 보낼 때 운영 체제에서는 호스트 이름을 MAC 주소로 변환하여 네트워크의 외부로 보낼 하드웨어(이더넷) 패킷을 생성한다.
ARP(Address Resolution Protocol)는 이 맵핑을 처리하는 프로토콜이며 arp 도구를 사용하여 현재 가지고 있는 호스트 및 해당 호스트 이름 또는 IP 주소에 대한 정보를 표시할 수 있다.
다른 시스템과 통신하려는 네트워크의 모든 시스템은 MAC 주소와 IP 주소로 구성된 패킷을 보내야 하므로 시스템의 ARP 캐시에 수집된 정보를 사용하여 네트워크에 있는 다른 시스템을 찾을 수 있다(Listing 16 참조).
Listing 16. arp 명령 사용하기
기존 허브 구조 대신 최신 이더넷 스위치를 사용할 경우에는 arp의 출력 정보를 특정 호스트와 보내고 받은 패킷으로 제한할 수 있다. 서버에서 arp를 실행할 수 있다면 더 긴 목록의 정보를 볼 수도 있지만 이 방법을 사용할 수 없는 경우도 있다.
일부 네트워크 스위치에는 모든 패킷이 에코되고 다른 네트워크 장치에 대한 정보를 수집하여 네트워크 구조를 파악하는 데 사용할 수 있는 네트워크 관리 또는 모니터링 포트가 있다. 이 정보에 액세스할 수 없는 경우에는 다른 강력한 도구를 통해 네트워크에 있는 호스트를 찾아야 한다.
네트워크에 있는 다른 호스트 검색하기
nmap 도구는 네트워크에 대해 다양한 유형의 검사를 수행하여 다양한 레벨의 정보를 찾고 확인할 수 있는 유틸리티이다. 기본 레벨에서는 지정된 네트워크 내의 모든 호스트를 찾는 데 사용할 수 있다.
이 기사의 앞 부분에서 호스트의 현재 IP 주소 및 네트워크 마스크 정보를 가져오는 방법을 살펴보았다. 이 정보를 사용하여 네트워크의 모든 호스트를 찾는 데 필요한 nmap의 기본 검색 매개변수를 설정할 수 있다. 이 정보를 지정하려면 CIDR 형식의 주소를 사용해야 한다. CIDR 형식은 호스트의 IP 주소와 네트워크 마스크의 비트 수를 사용하여 네트워크의 범위를 결정한다.
예제 호스트에서 192.168.1.25는 IP 주소이고 네트워크 마스크는 255.255.252.0이다. 이는 22비트에 해당한다. 즉, 첫 번째 부분에 8비트, 두 번째 부분에 8비트 그리고 세 번째 부분에 6비트가 해당한다.
이 주소를 사용하여 nmap을 실행하면 범위 내의 모든 단일 IP 주소(예를 들어, 192.168.0.0과 192.168.3.255 사이의 모든 주소)에 대한 검색이 수행되고 응답하는 호스트가 확인된다.
표준 ping 프로토콜을 사용하는 테스트나 다른 네트워크 포트를 시도하는 강력한 테스트(ping 프로토콜을 사용할 수 없는 경우)를 포함한 여러 가지 테스트를 수행할 수 있다. 예를 들어, ping 테스트를 수행하면 Listing 17과 같은 호스트 목록이 표시된다.
Listing 17. nmap을 실행하여 IP 주소 범위 검색하기
ping 검사를 수행하면 네트워크에 있는 다른 시스템을 매우 빠르게 확인할 수 있다. 이 경우에는 11개의 호스트가 검색되었지만 이들 중 일부 호스트는 이름을 다시 확인할 수 없다. 이는 DNS 구성에 오류가 있음을 나타낸다. 일부 시스템에서는 역방향 조회(IP 주소로 이름을 확인하는 조회)를 사용하여 클라이언트 IP 주소가 변조되지 않았는지 확인하는 보안 검사를 수행하므로 이 오류는 수정되어야 한다.
네트워크에 있는 다른 서비스 찾기
ping 검사가 유용하기는 하지만 개별 시스템에서 실제로 노출하고 있는 서비스를 알고 싶을 때는 TCP 검사를 사용해야 한다. TCP 검사를 수행하면 nmap이 목록 내에 있는 각 호스트에서 TCP/IP 프로토콜을 사용하는 포트를 열려고 시도하므로 더 많은 시간이 소요된다. 이 검사는 네트워크에 있는 호스트를 표시하고 각 호스트의 열려 있는 포트에 대한 세부 정보를 제공하려는 경우에 효과적이다. Listing 18에서 이 검사의 출력 예제를 볼 수 있다.
Listing 18. TCP 검사 사용하기
이 출력을 보면 다양한 서비스를 제공하는 수많은 서버가 네트워크에 있다는 것을 알 수 있다. 예를 들어, 192.168.0.1의 장치는 HTTP 및 HTTP 프록시 서비스를 제공한다. 또한 bear.mcslp.pri는 http뿐만 아니라 smtp, imap, nfs 및 MySQL 서비스도 제공한다.
이러한 서비스에 대한 구체적인 정보를 확인하려는 경우에는 다시 한번 nmap을 버전 인수와 함께 사용하여 특정 호스트에 열려 있는 프로토콜 및 포트에 대한 구체적인 버전 정보 목록을 확인할 수 있다.
예를 들어, 메인 서버처럼 보이는 호스트(bear)를 검사해 보면 이러한 각 포트에서 실행되고 있는 서비스를 매우 정확히 파악할 수 있다(Listing 19 참조).
Listing 19. 버전 인수와 함께 nmap 사용하기
이 출력에서는 수많은 특정 서비스를 볼 수 있으며, 각 포트에서 제공하는 버전 정보뿐 아니라 애플리케이션 정보까지도 확인할 수 있다.
네트워크에서 식별되지 않은 호스트 확인하기
네트워크에 있는 호스트를 검색한 후 호스트에 대한 정보 특히, 즉시 인식되지 않는 호스트에 대한 정보를 확인할 수 있다. TCP 포트 검사는 호스트에서 지원하고 있는 서비스를 보여 주기는 하지만 반드시 모든 정보를 보여 주는 것은 아니다. 일부 장치 및 시스템의 경우에는 네트워크의 서비스를 즉시 확인할 수 없는 방식으로 포트를 노출하기도 하며 더 나아가 노출하지 않을 수도 있다.
nmap 운영 체제 검사는 열려 있는 포트를 검사한 후 다양한 서비스가 실행되고 있는 운영 체제를 확인한다. 이 기능은 네트워크에서 열려 있는 포트와 새 장치가 있는 서버를 식별하는 기능과는 다르다.
예를 들어, Listing 20에서와 같이 bear라는 서버에 대해 운영 체제 식별을 실행하면 일반적인 Linux 버전이 시스템에서 실행되고 있다는 것을 식별할 수 있으며 이는 해당 시스템이 표준 컴퓨터임을 나타낸다.
Listing 20. nmap 운영 체제 검사
OS 검사는 완벽하지 않으며 finger printing 기술을 사용하여 열려 있는 포트 및 리턴된 버전 정보의 의미를 확인한다. 예를 들어, Listing 21의 검사에서는 포트 유형을 기반으로 잠재적 운영 체제의 수를 식별한다.
Listing 21. 잠재적 운영 체제의 수를 식별하는 검사
nmap 검사는 로컬 및 원격 네트워크 둘 다에 대해 실행할 필요는 없다. 위 원격 테스트에서 nmap은 패킷이 대상 시스템에 도달하기 전까지 통과해야 하는 다양한 시스템을 확인했다. 사용자의 시스템과 다른 시스템 사이에 있는 다양한 장치를 파악하는 작업은 네트워크 레이아웃을 이해하고 파악하는 과정의 마지막 단계이다.
네트워크 구조 결정하기
IP 네트워크 패킷이 네트워크에서 전송될 경우, 시스템이 패킷을 다른 네트워크 또는 시스템으로 전달할 때마다 특수 카운터가 증가된다. 패킷 전달은 여러 다양한 시스템에서 발생한다. 여러 네트워크 스위치가 함께 연결되어 있는 경우 각 허브는 자신을 새 장치로 식별할 수 있다. 또한 무선 액세스 포인트와 기존 라우터 모두 패킷을 전달하는 장치이므로 패킷의 네트워크 경로의 일부로 간주된다.
대부분의 네트워크 환경에서 로컬 네트워크에 있는 허브, 스위치 및 기타 구성 요소는 이 값을 증가시키지 않는다. 하지만 외부 네트워크로까지 시선을 넓히면 네트워크 규모가 더 커지고 복잡해지므로 개별 패킷의 경로를 이해할 수 있다면 성능 및 연결 문제를 식별하는 데 많은 도움이 된다.
호스트와의 통신 경로에 대한 정보를 표시하는 데 주로 사용되는 도구는 traceroute이다. 이 도구는 현재 호스트에서 대상까지의 지정된 경로 내에 있는 각 호스트의 IP 주소를 확인한다. 대상 호스트가 로컬 호스트 자신이면 직접 경로로 표시된다(Listing 22 참조).
Listing 22. traceroute 사용하기
Listing 23에서는 로컬 라우터나 브리지를 통해 액세스할 수 있는 로컬 네트워크에 있는 호스트를 보여 준다.
Listing 23. 로컬 네트워크에 있는 호스트
원격 네트워크에 대한 연결은 패킷이 통과하게 되는 각 라우터와 단계를 보여 준다(Listing 24 참조.
Listing 24. 원격 네트워크 연결
호스트 목록을 확인하는 nmap과 함께 이 방법을 사용하면 네트워크에 있는 호스트에 대한 정보와 이러한 시스템에 도달하는 데 사용되는 라우터 및 시스템에 대한 정보를 훨씬 더 자세히 볼 수 있다.
결론
이 튜토리얼에서는 네트워크에 있는 호스트, 이러한 호스트에 액세스하는 방법, 연결되어 있는 장치 및 시스템, 제공되는 서비스 및 시스템 등에 대한 다양한 정보를 확인하는 데 사용할 수 있는 여러 가지 UNIX 도구 및 기술을 살펴보았다.
이제 이러한 기술을 통해 UNIX 환경에 액세스하여 네트워크 구성을 확인할 수 있어야 하며, 필요한 정보를 기록하여 문제점 및 그 이유를 파악하고 해결 방법까지도 알아낼 수 있어야 한다.
기사의 원문보기
http://www.ibm.com/developerworks/kr/library/tutorial/au-unixnetworkanalysis/section2.html
UNIX 네트워크 분석
UNIX 시스템 네트워크 구성 이해하기요약: 여러 가지 도구를 사용하여 네트워크에 대한 정보를 찾아볼 수 있습니다. 네트워크 레이아웃, 패킷의 이동 위치, 사용자가 수행 중인 작업 등을 확인하려면 네트워크 레이아웃과 네트워크에서 수행 중인 작업을 보여 주는 다양한 도구를 사용해야 합니다. 이 튜토리얼에서는 UNIX® 네트워크의 트래픽과 컨텐츠를 모니터링하는 기술과 네트워크의 문제점을 파악하여 진단하는 방법에 대해 설명합니다.
원문 게재일: 2009 년 5 월 05 일
난이도: 중급
PDF: A4 and Letter (61 KB | 22 pages)Get Adobe® Reader®
페이지뷰: 4199 회
의견: 0 (의견 추가)
난이도: 중급
PDF: A4 and Letter (61 KB | 22 pages)Get Adobe® Reader®
페이지뷰: 4199 회
의견: 0 (의견 추가)
이 튜토리얼은 다양한 장치에서 실행되고 있는 서비스 및 시스템을 포함한 네트워크 구조 및 구성에 대한 정보를 효율적으로 검색 및 확인할 수 있는 방법을 찾고 있는 UNIX 시스템 관리자를 대상으로 한다. 이 튜토리얼을 이해하려면 UNIX 운영 체제, 네트워크 및 IP(Internet protocol)의 작동 방법에 대한 기본 지식이 있어야 한다.
이 튜토리얼의 정보
새 UNIX 시스템뿐 아니라 기존 UNIX 시스템의 복잡한 작동 방법을 이해하는 데 있어서 핵심이 되는 부분은 네트워크 구성이다. 문제점을 올바르게 식별하고 잠재적인 문제점을 예방하기 위해서는 네트워크의 여러 가지 특성을 숙지하고 있어야 한다. 몇 가지 기본적인 도구와 명령을 사용하여 단일 시스템의 구성에 대한 여러 가지 정보를 확인할 수 있으며, 이 기본적인 이해를 바탕으로 네트워크의 나머지 부분에 대한 구성도 이해할 수 있다. 또한 몇 가지 추가 도구를 사용하여 네트워크 내의 추가 시스템 및 서비스에 대한 정보를 확인함으로써 이해의 지평을 넓힐 수 있다.
이 튜토리얼에서는 UNIX 환경 내에서 몇 가지 기본 도구를 사용하여 시스템의 구성 정보를 확인한다. 이러한 도구와 출력되는 정보를 이해하게 되면 시스템 네트워크 구성과 네트워크의 작동 방법에 이해의 깊이도 깊어질 것이다. 또한 더 넓은 네트워크를 검색하여 네트워크의 세부 정보, 잠재적 보안 문제 및 문제가 발생했을 때 문제점을 식별 및 진단하는 데 도움이 되는 주요 정보를 제공할 수 있는 도구 및 솔루션에 대해서도 살펴본다.
호스트의 네트워크 이해
네트워크를 이해하는 과정의 첫 번째 단계는 현재 사용 중인 시스템의 네트워크 구성을 이해하는 것이다. 이 단계에서는 현재 호스트의 IP 주소, DNS 구성 및 현재 호스트에서 연결하여 통신할 수 있는 시스템 등에 대한 여러 가지 기본적인 정보를 확인하게 된다.
구성 정보 찾기
작업 중인 시스템의 현재 구성을 보면 사용자의 환경에 대한 기본 정보를 파악할 수 있다. 우선 현재 시스템의 IP 주소와 네트워크 마스크를 확인할 수 있다. 이러한 두 값이 있으면 현재 시스템의 주소뿐만 아니라 현재 시스템에서 직접(예를 들어, 라우터를 사용하지 않고) 연결할 수 있는 네트워크 상의 다른 시스템을 확인할 수 있다.
IP 주소를 확인하기 전에 hostname 명령을 사용하여 시스템의 호스트 이름을 가져온다(Listing 1 참조).
Listing 1. 호스트 이름 가져오기
$ hostname sulaco |
-a 옵션을 지정하고서 ifconfig 명령을 실행하면 사용자의 시스템에 구성되어 있는 모든 네트워크 장치의 현재 구성 정보가 표시된다. 예를 들어, Listing 2에서는 Solaris 시스템에서 실행한 ifconfig 명령의 출력을 보여 준다. Listing 2. Solaris에서 실행한 ipconfig의 출력
$ ifconfig -a
lo0: flags=2001000849<UP,LOOPBACK,RUNNING,MULTICAST,IPv4,VIRTUAL> mtu 8232 index 1
inet 127.0.0.1 netmask ff000000
pcn0: flags=201004843<UP,BROADCAST,RUNNING,MULTICAST,DHCP,IPv4,CoS>
mtu 1500 index 2
inet 192.168.1.25 netmask fffffc00 broadcast 192.168.3.255
lo0: flags=2002000849<UP,LOOPBACK,RUNNING,MULTICAST,IPv6,VIRTUAL> mtu 8252 index 1
inet6 ::1/128
pcn0: flags=202004841<UP,RUNNING,MULTICAST,DHCP,IPv6,CoS> mtu 1500 index 2
inet6 fe80::20c:29ff:fe7f:dc5/10
|
이 출력을 보면 루프백 장치인 lo0이 있고, 이 장치의 주소가 로컬 호스트의 일반적인 주소인 127.0.0.1이라는 것을 알 수 있다. 또한 이 장치에 동등한 IPv6 주소도 있다는 것을 알 수 있다.
pcn0 장치는 네트워크 주소 192.168.1.25와 네트워크 마스크 fffffc00(255.255.252.0에 해당)으로 구성되어 있다. 또한 이 장치의 주소는 DHCP를 사용하여 설정되었다는 것을 알 수 있다(DHCP 플래그 목록 참조).
특히 네트워크 마스크가 중요하다. 왜냐하면 네트워크 마스크만 있으면 사용자가 직접 연결되어 있는 네트워크의 크기(등록된 IP 주소의 관점에서)를 확인할 수 있기 때문이다. 이 장치의 네트워크 마스크인 255.255.252.0은 클래스 C 주소가 4개임을 나타낸다(256(최대 호스트 수) - 252(마스킹된 호스트 수) = 4).
네트워크 마스크와 구성된 IP 주소를 결합하여 로컬 네트워크에 있는 IP 주소의 범위를 추측할 수 있다. 일반적으로 IP 블록은 전체 그룹별로 차례대로 분할되기 때문에 이 네트워크의 IP 주소 범위는 192.168.0.0부터 192.168.3.255까지이다. 4개의 클래스 C 주소로 구성된 네트워크 마스크를 사용하면 일반적으로 전체 범위(192.168.0.0-192.168.255.255)가 동일한 블록들로 분할되므로 주소 접두어가 192.168.1.x인 주소는 4개의 주소 블록 중 첫 번째 블록에 있다.
이 정보(및 세부 사항)는 운영 체제마다 각기 다른 방식으로 표시된다. Listing 3에서는 Linux® 시스템의 출력을 보여 준다.
Listing 3. Linux 시스템의 출력
eth0 Link encap:Ethernet HWaddr 00:1d:60:1b:9a:2d
inet addr:192.168.0.2 Bcast:192.168.3.255 Mask:255.255.252.0
inet6 addr: fe80::21d:60ff:fe1b:9a2d/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:2371085881 errors:36 dropped:0 overruns:0 frame:36
TX packets:2861233776 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:913269364222 (850.5 GiB) TX bytes:3093820025338 (2.8 TiB)
Interrupt:23 Base address:0x4000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:279755697 errors:0 dropped:0 overruns:0 frame:0
TX packets:279755697 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:388038389807 (361.3 GiB) TX bytes:388038389807 (361.3 GiB)
|
Listing 4에서는 Mac OS X™ 시스템의 출력을 보여 준다.
Listing 4. Mac OS X 시스템의 출력
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.101 netmask 0xfffffc00 broadcast 192.168.3.255
ether 00:16:cb:a0:3b:cb
media: autoselect (1000baseT <full-duplex,flow-control>) status: active
supported media: autoselect 10baseT/UTP <half-duplex> 10baseT/UTP
<full-duplex> 10baseT/UTP <full-duplex,hw-loopback> 10baseT/UTP
<full-duplex,flow-control> 100baseTX <half-duplex> 100baseTX
<full-duplex> 100baseTX <full-duplex,hw-loopback> 100baseTX
<full-duplex,flow-control> 1000baseT <full-duplex> 1000baseT
<full-duplex,hw-loopback> 1000baseT <full-duplex,flow-control> none
fw0: flags=8822<BROADCAST,SMART,SIMPLEX,MULTICAST> mtu 2030
lladdr 00:17:f2:ff:fe:7b:84:d6
media: autoselect <full-duplex> status: inactive
supported media: autoselect <full-duplex>
en1: flags=8822<BROADCAST,SMART,SIMPLEX,MULTICAST> mtu 1500
ether 00:17:f2:9b:3d:38
media: autoselect (<unknown type>)
supported media: autoselect
en5: flags=8963<UP,BROADCAST,SMART,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::21c:42ff:fe00:8%en5 prefixlen 64 scopeid 0x7
inet 10.211.55.2 netmask 0xffffff00 broadcast 10.211.55.255
ether 00:1c:42:00:00:08
media: autoselect status: active
supported media: autoselect
en6: flags=8963<UP,BROADCAST,SMART,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::21c:42ff:fe00:9%en6 prefixlen 64 scopeid 0x8
inet 10.37.129.2 netmask 0xffffff00 broadcast 10.37.129.255
ether 00:1c:42:00:00:09
media: autoselect status: active
supported media: autoselect
|
일반적으로 모든 운영 체제의 출력에서 연결된 네트워크 장치의 인터넷 주소와 네트워크 마스크를 볼 수 있다. 여러 개의 네트워크 장치가 있는 경우에는 각 장치에 대한 정보가 출력에 표시되며 사용자는 단 하나의 시스템에서 폭넓은 범위의 다양한 네트워크 및 시스템에 연결할 수 있다.
이름 확인 서비스 찾기
현재 시스템의 구성을 확인하는 과정의 다음 단계는 다른 시스템의 서비스에 액세스할 때 사용자의 시스템 이름 및 도메인 이름을 IP 주소로 변환하는 이름 서비스 시스템의 구성과 관련된다.
대부분의 시스템에서 이 구성은 /etc/nsswitch.conf 파일을 통해 설정하며, 이 파일에는 다양한 이름 서비스(호스트, 사용자 등)의 목록과 이름 확인에 사용할 다양한 서비스(DNS, NIS 또는 로컬 파일)의 순서가 들어 있다. Listing 5에서 이 파일의 예를 볼 수 있다.
Listing 5. 이름 서비스 시스템 확인하기
passwd: files group: files hosts: files dns ipnodes: files dns networks: files protocols: files rpc: files ethers: files netmasks: files bootparams: files publickey: files netgroup: files automount: files aliases: files services: files printers: user files auth_attr: files prof_attr: files project: files tnrhtp: files tnrhdb: files |
예를 들어, Listing 5에서 호스트 이름 정보는 시스템에 있는 로컬 파일(예: /etc/hosts)과 DNS(Domain Name System)를 차례대로 검색하여 확인한다.
DNS가 구성되어 있는 경우에는 /etc/resolv.conf 파일에서 이름을 IP 주소로 변환하는 데 사용 중인 시스템을 확인할 수 있다. Listing 6에서는 이 파일의 예제를 보여 준다.
Listing 6. 이름을 IP 주소로 변환하는 데 사용 중인 시스템
domain example.pri nameserver 192.168.0.2 nameserver 192.168.0.3 |
이 정보는 해당 시스템의 정보를 직접 쿼리하려는 경우에 유용하게 사용할 수 있다. dig 및 nslookup과 같은 도구를 사용하여 이름 및 IP 주소의 이름 서비스 및 확인에 대한 정보를 추출할 수 있다.
경로 검사하기
네트워크의 외부에 있는(즉, 현재 IP 주소와 비교하여 네트워크 마스크의 범위에서 벗어난) 호스트는 다른 시스템으로 전달되기 위해 라우터로 전송된다. 라우터는 부서 간, 다양한 물리적 사이트 및 인터넷과 같은 공용 외부 사이트를 포함한 네트워크의 모든 레벨에서 사용할 수 있다.
사용자의 시스템에서 '로컬' 네트워크의 외부에 있는 시스템과 통신하려는 경우 netstat 명령을 사용하여 연결된 시스템 또는 라우터를 구별할 수 있다. 예를 들어, 아래 Listing 7에서는 Solaris 시스템에서 실행한 netstat 명령의 출력을 보여 준다.
Listing 7. netstat 명령
$ netstat -r Routing Table: IPv4 Destination Gateway Flags Ref Use Interface -------------------- -------------------- ----- ----- ---------- --------- default voyager.example.pri UG 1 139 pcn0 192.168.0.0 solaris2.example.pri U 1 447 pcn0 solaris2 solaris2 UH 1 35 lo0 Routing Table: IPv6 Destination/Mask Gateway Flags Ref Use If --------------------------- --------------------------- ----- --- ------- ----- fe80::/10 fe80::20c:29ff:fe7f:dc5 U 1 0 pcn0 solaris2 solaris2 UH 1 0 lo0 |
기본 경로는 현재 네트워크의 외부에 있거나 특정 IP 주소 또는 IP 주소 범위의 다른 경로에서 아직 처리되지 않은 패킷을 라우팅하는 데 사용되는 게이트웨이(라우터)를 보여 준다.
현재 이름 서비스가 작동되지 않거나 올바른 정보를 리턴하지 않는 경우에는 이 정보를 확인할 필요가 있으며 -n 옵션을 지정하여 이름 대신 IP 주소를 사용하여 이 정보를 표시할 수 있다.
지원되는 서비스 검사하기
netstat 명령은 현재 호스트에서 공유 또는 노출하고 있는 서비스를 확인할 때도 사용할 수 있다. 이러한 서비스에는 DNS, NFS, 웹 서비스 및 기타 정보를 포함한 모든 네트워크 서비스가 포함된다. 표시된 정보는 클라이언트 연결을 대기하기 위해 '수신 중' 상태로 열려 있는 포트 또는 이미 열려 있는 상태에서 클라이언트와 통신 중인 포트를 기반으로 한다.
이 정보를 통해 서비스가 실행 중인지 여부를 확인할 수 있을 뿐 아니라 표준 보안 검사의 일환으로 시스템이 공유되고 있거나 필요 이상의 위험에 노출되어 있는지 여부를 확인할 수 있다.
Listing 8에서는 이 명령의 출력 예제를 볼 수 있다. 이 예제에서는
-a를 사용하여 새 연결에 대해 설정된 상태로 수신 중인 모든 열려 있는 포트 및 서비스를 표시한다. 기본적으로 netstat 명령은 열려 있는 UNIX 도메인 소켓을 보여 주며 이러한 소켓은 현재 시스템에만 액세스할 수 있다. 간단히 설명하기 위해 이 출력 예제에서는 이들 소켓을 생략했다. Listing 8.
-a를 사용한 출력$ netstat -a Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 *:imaps *:* LISTEN tcp 0 0 *:nfs *:* LISTEN tcp 0 0 *:vmware-authd *:* LISTEN tcp 0 0 localhost:10024 *:* LISTEN tcp 0 0 localhost:10025 *:* LISTEN tcp 0 0 *:mysql *:* LISTEN tcp 0 0 *:imap *:* LISTEN tcp 0 0 localhost:783 *:* LISTEN tcp 0 0 *:sunrpc *:* LISTEN tcp 0 0 bear.example.pri:http *:* LISTEN tcp 0 0 *:cisco-sccp *:* LISTEN tcp 0 0 *:47506 *:* LISTEN tcp 0 0 *:34452 *:* LISTEN tcp 0 0 172.16.217.1:domain *:* LISTEN tcp 0 0 192.168.92.1:domain *:* LISTEN tcp 0 0 bear.example.pri:domain *:* LISTEN tcp 0 0 localhost:domain *:* LISTEN tcp 0 0 *:53941 *:* LISTEN tcp 0 0 *:3128 *:* LISTEN tcp 0 0 localhost:rndc *:* LISTEN tcp 0 0 *:smtp *:* LISTEN tcp 0 0 bear.example.pri:imap sulaco.example.p:65452 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65459 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65412 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65417 ESTABLISHED tcp 0 0 bear.example.pri:mysq bear.example.pri:35475 TIME_WAIT tcp 0 0 bear.example.pri:http sulaco.example.p:49603 FIN_WAIT2 tcp 0 0 bear.example.pri:nfs sulaco.example.p:49552 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65433 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65431 ESTABLISHED tcp 1 0 bear.example.pri:nfs sulaco.example.p:51900 CLOSE_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65415 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65475 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65472 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65429 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65430 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65438 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65443 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65418 ESTABLISHED tcp 0 0 bear.example.pri:nfs narcissus.exampl:62968 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65448 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65423 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65468 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65445 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65476 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65453 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65456 ESTABLISHED tcp 1 0 bear.example.pri:nfs sulaco.example.p:59172 CLOSE_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65416 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65439 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65441 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65446 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65470 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65450 ESTABLISHED tcp 0 0 bear.example.pri:nfs sulaco.example.p:65320 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65465 ESTABLISHED tcp 0 0 bear.example.pri:36230 solaris2.vmbear.mcs:ssh ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65421 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65464 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65474 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:64955 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65473 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65461 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65454 ESTABLISHED tcp 0 0 bear.example.pri:http sulaco.example.p:49608 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65471 ESTABLISHED tcp 0 0 localhost:50123 localhost:ssh ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65420 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65466 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65463 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65451 ESTABLISHED tcp 0 0 bear.example.pri:35471 bear.example.pri:mysql TIME_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65457 ESTABLISHED tcp 1 0 bear.example.pri:nfs sulaco.example.p:53877 CLOSE_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65432 ESTABLISHED tcp 0 0 bear.example.pri:mysql bear.example.pri:35470 TIME_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65467 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65414 ESTABLISHED tcp 0 0 bear.example.pri:50112 bear.example.pri:imap TIME_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65462 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65460 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65469 ESTABLISHED tcp 0 0 bear.example.pri:imap sulaco.example.p:65422 ESTABLISHED tcp 0 0 bear.example.pri:50110 bear.example.pri:imap TIME_WAIT tcp 0 0 bear.example.pri:50111 bear.example.pri:imap TIME_WAIT tcp 0 0 bear.example.pri:imap sulaco.example.p:65442 ESTABLISHED tcp6 0 0 [::]:imaps [::]:* LISTEN tcp6 0 0 [::]:11211 [::]:* LISTEN tcp6 0 0 [::]:imap [::]:* LISTEN tcp6 0 0 [::]:cisco-sccp [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN tcp6 0 0 localhost:rndc [::]:* LISTEN tcp6 0 0 [::]:https [::]:* LISTEN tcp6 0 0 bear.example.pri:ssh sulaco.example.p:52786 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:56220 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:63895 ESTABLISHED tcp6 0 0 localhost:ssh localhost:50123 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:60914 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:64669 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:56053 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:52268 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:49528 ESTABLISHED tcp6 0 0 bear.example.pri:ssh sulaco.example.p:65408 ESTABLISHED udp 0 0 *:nfs *:* udp 0 0 *:42498 *:* udp 0 0 *:54680 *:* udp 0 0 172.16.217.1:domain *:* udp 0 0 192.168.92.1:domain *:* udp 0 0 bear.example.p:domain *:* udp 0 0 localhost:domain *:* udp 0 0 *:45495 *:* udp 0 0 *:icpv2 *:* udp 0 0 *:bootps *:* udp 0 0 *:964 *:* udp 0 0 *:11211 *:* udp 0 0 *:sunrpc *:* udp 0 0 *:50042 *:* raw 0 0 *:icmp *:* 7 |
이 출력에서 볼 수 있듯이 이 시스템에서는 매우 많은 작업이 수행되고 있다. 세 번째 열은 열려 있거나 수신 중인 각 연결에 대한 호스트 이름과 포트(콜론으로 구분)를 보여 준다. TCP 또는 UDP 서비스 번호가 알려진 포트 번호(/etc/services 파일 내에 정의된 포트 번호)와 일치하면 해당 서비스 이름이 출력에 표시된다. 호스트의 경우 호스트 이름, 대체 IP 주소 또는 '*' 기호가 표시된다. 별표는 해당 서비스 및 포트가 모든 IP 주소에서 열려 있고 수신 중임을 나타낸다.
예를 들어, Listing 9의 출력에서 시스템이 NFS를 지원하도록 구성되어 있고 열린(설정된) 연결이 있음을 알 수 있다.
Listing 9. NFS를 지원하도록 구성된 시스템
$ netstat -a|grep nfs tcp 0 0 *:nfs *:* LISTEN tcp 1 0 bear.example.pri:nfs sulaco.example.p:51900 CLOSE_WAIT tcp 0 0 bear.example.pri:nfs narcissus.example.p:62968 ESTABLISHED tcp 1 0 bear.example.pri:nfs sulaco.example.p:59172 CLOSE_WAIT tcp 0 0 bear.example.pri:nfs sulaco.example.p:65320 ESTABLISHED tcp 1 0 bear.example.pri:nfs sulaco.example.p:53877 CLOSE_WAIT udp 0 0 *:nfs *:* |
또한 이 출력에서는 현재 시스템과 통신 중인 시스템을 확인할 수도 있다. 예를 들어, 다섯 번째 열을 정렬한 다음 목록에서 중복된 항목을 제거하여 현재 시스템에 연결된 시스템 목록을 추출할 수 있다(Lisiting 10 참조).
Listing 10. 연결된 시스템 목록 추출하기
$ netstat -a|egrep 'tcp|udp'|grep ESTABLISHED|awk '{ print $5; }'|cut -d: -f1|sort|uniq
localhost
narcissus.mcslp.p
nautilus.wireless
polarbear.wireles
solaris2.vmbear.mcs
sulaco.mcslp.pri
|
이 기능은 인식하지 못하고 있거나 원하지 않는 사용자 또는 컴퓨터가 현재 시스템에 연결되어 있는지 확인할 때 유용하게 사용할 수 있다.
이러한 다른 시스템에 대한 정보를 확인하려면 먼저 사용자의 네트워크에 있는 다른 컴퓨터를 검색해야 한다.
다른 호스트에 대한 정보 찾기
이제 로컬 시스템에 대한 기본 정보를 알고 있으므로 이제 네트워크의 다른 시스템도 검색하여 사용 가능한 시스템과 각 시스템에서 제공하는 서비스를 확인할 수 있다. 올바른 도구를 사용하여 이러한 시스템에서 실행 중인 운영 체제와 공유하고 있는 서비스까지도 확인할 수 있다.
호스트 검사하기
원격 시스템을 가장 쉽고 명확하게 검사하는 방법은 ping 도구를 사용하여 특정 호스트가 실행 중이고 사용 가능한지 여부를 검사하는 것이다. 매우 단순한 작업을 수행하는 ping 도구는 응답을 요청하는 원격 호스트에 패킷을 보낸 후 응답이 수신되면 시간 차이를 계산한다. 이렇게 패킷을 보내고 받는데 걸린 시간을 사용하여 현재 시스템과 대상 시스템의 거리를 표시할 수 있다.
예를 들어, 사용자의 네트워크에 있는 시스템에 대해 ping을 실행할 경우에는 ping 패킷에 대한 응답이 매우 빠르게 수신된다(Listing 11 참조).
Listing 11. 사용자의 네트워크에 있는 시스템에 대해 ping 실행하기
$ ping bear PING bear.mcslp.pri (192.168.0.2): 56 data bytes 64 bytes from 192.168.0.2: icmp_seq=0 ttl=64 time=0.154 ms 64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.162 ms 64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.149 ms 64 bytes from 192.168.0.2: icmp_seq=3 ttl=64 time=0.161 ms 64 bytes from 192.168.0.2: icmp_seq=4 ttl=64 time=0.162 ms 64 bytes from 192.168.0.2: icmp_seq=5 ttl=64 time=0.161 ms ^C --- bear.mcslp.pri ping statistics --- 6 packets transmitted, 6 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.149/0.158/0.162/0.005 ms |
ping 도구는 구현 형태에 따라 각기 다른 방식으로 작동한다. Linux 및 Mac OS X의 경우 이 도구는 기본적으로 패킷을 지속적으로 보내면서 사용자가 Ctrl-C를 눌러서 애플리케이션을 종료할 때까지 응답을 기다린다.
Solaris™, AIX® 및 일부 기타 UNIX 운영 체제에서는 추가 인수 없이 ping 도구를 실행하면 원격 호스트가 응답했는지 여부만 표시된다(Listing 12 참조).
Listing 12. 기타 UNIX 운영 체제에서 추가 인수 없이 ping 실행하기
$ ping bear bear is alive |
더 긴 테스트를 수행하려면 Listing 13과 같이
-s 옵션을 사용한다. Listing 13.
-s 옵션을 사용하여 ping 실행하기$ ping -s bear PING bear: 56 data bytes 64 bytes from bear.mcslp.pri (192.168.0.2): icmp_seq=0. time=0.288 ms 64 bytes from bear.mcslp.pri (192.168.0.2): icmp_seq=1. time=0.247 ms 64 bytes from bear.mcslp.pri (192.168.0.2): icmp_seq=2. time=0.208 ms 64 bytes from bear.mcslp.pri (192.168.0.2): icmp_seq=3. time=0.230 ms ^C ----bear PING Statistics---- 4 packets transmitted, 4 packets received, 0% packet loss round-trip (ms) min/avg/max/stddev = 0.208/0.243/0.288/0.034 |
각 행의 time 필드에는 각 패킷에 대한 속도와 지연 시간(응답이 수신되기 전까지의 지연 시간 및 활동 레벨을 나타내기도 함)이 표시된다. 출력을 중지하면 보내고 받은 패킷의 수와 시간 통계에 대한 요약 정보가 표시된다.
ping 패킷이 이동해야 하는 거리가 멀수록 원격 호스트의 응답 시간이 길어집니다. 예를 들어, 인터넷에 있는 공용 서버에 대해 ping을 실행할 경우에는 응답 패킷을 수신하는 데 걸린 시간이 상당히 커집니다(Listing 14 참조).
Listing 14. 인터넷에 있는 공용 서버에 대해 ping 실행하기
$ ping www.example.com PING www.example.com (67.205.21.169) 56(84) bytes of data. 64 bytes from mcslp.com (67.205.21.169): icmp_seq=1 ttl=44 time=193 ms 64 bytes from mcslp.com (67.205.21.169): icmp_seq=2 ttl=44 time=194 ms 64 bytes from mcslp.com (67.205.21.169): icmp_seq=3 ttl=44 time=197 ms 64 bytes from mcslp.com (67.205.21.169): icmp_seq=4 ttl=44 time=194 ms ^C --- www.example.com ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3039ms rtt min/avg/max/mdev = 193.737/195.120/197.123/1.353 ms |
인터넷 서비스에 연결하는 데 걸린 시간(193ms)과 로컬 호스트에 연결하는 데 걸린 시간(0.23ms)을 비교해 보자.
ping 도구를 사용하면 연결하려는 원격 호스트에 도달할 수 있는지 여부도 빠르게 확인할 수 있다. 존재하지 않는 호스트에 대해 ping을 실행하면 특정 오류가 리턴된다(Listing 15 참조).
Listing 15. 존재하지 않는 호스트에 대해 ping 실행하기
$ ping notinhere PING notinhere (192.168.0.110) 56(84) bytes of data. >From bear.mcslp.pri (192.168.0.2) icmp_seq=1 Destination Host Unreachable >From bear.mcslp.pri (192.168.0.2) icmp_seq=2 Destination Host Unreachable >From bear.mcslp.pri (192.168.0.2) icmp_seq=3 Destination Host Unreachable ^C --- notinhere ping statistics --- 5 packets transmitted, 0 received, +3 errors, 100% packet loss, time 4039ms |
ping 도구를 사용하려면 네트워크에 있는 다른 시스템에 대한 정보를 알아야 한다. 이제 이름이나 IP 주소를 사용하지 않고 네트워크에 있는 호스트를 확인하는 방법을 살펴보자.
네트워크에 있는 호스트 검색하기
이더넷 네트워크 시스템(및 기타 시스템) 내에서 네트워크의 모든 장치는 하드웨어 네트워크 장치와 연관된 고유 주소를 가지고 있다. MAC(Media Access Control) 번호는 네트워크 장치를 고유하게 식별하며 IP(Internet Protocol)와 같은 상위 레벨 프로토콜을 사용하여 MAC 주소와 호스트 이름을 연관시킬 수 있다.
MAC 주소는 운영 체제에서 패킷을 네트워크의 외부로 보낼 때(및 그 반대의 경우에) 사용된다. 패킷을 특정 호스트 이름으로 보낼 때 운영 체제에서는 호스트 이름을 MAC 주소로 변환하여 네트워크의 외부로 보낼 하드웨어(이더넷) 패킷을 생성한다.
ARP(Address Resolution Protocol)는 이 맵핑을 처리하는 프로토콜이며 arp 도구를 사용하여 현재 가지고 있는 호스트 및 해당 호스트 이름 또는 IP 주소에 대한 정보를 표시할 수 있다.
다른 시스템과 통신하려는 네트워크의 모든 시스템은 MAC 주소와 IP 주소로 구성된 패킷을 보내야 하므로 시스템의 ARP 캐시에 수집된 정보를 사용하여 네트워크에 있는 다른 시스템을 찾을 수 있다(Listing 16 참조).
Listing 16. arp 명령 사용하기
$ arp Address HWtype HWaddress Flags Mask Iface gendarme.mcslp.pri ether 00:1B:2F:F0:39:6A C eth0 narcissus.mcslp.pri ether 00:16:CB:85:2D:15 C eth0 solaris2.vmbear.mcslp.p ether 00:0C:29:7F:0D:C5 C eth0 nautilus.wireless.mcslp ether 00:17:F2:40:4D:1B C eth0 sulaco.mcslp.pri ether 00:16:CB:A0:3B:CB C eth0 |
기존 허브 구조 대신 최신 이더넷 스위치를 사용할 경우에는 arp의 출력 정보를 특정 호스트와 보내고 받은 패킷으로 제한할 수 있다. 서버에서 arp를 실행할 수 있다면 더 긴 목록의 정보를 볼 수도 있지만 이 방법을 사용할 수 없는 경우도 있다.
일부 네트워크 스위치에는 모든 패킷이 에코되고 다른 네트워크 장치에 대한 정보를 수집하여 네트워크 구조를 파악하는 데 사용할 수 있는 네트워크 관리 또는 모니터링 포트가 있다. 이 정보에 액세스할 수 없는 경우에는 다른 강력한 도구를 통해 네트워크에 있는 호스트를 찾아야 한다.
네트워크에 있는 다른 호스트 검색하기
nmap 도구는 네트워크에 대해 다양한 유형의 검사를 수행하여 다양한 레벨의 정보를 찾고 확인할 수 있는 유틸리티이다. 기본 레벨에서는 지정된 네트워크 내의 모든 호스트를 찾는 데 사용할 수 있다.
이 기사의 앞 부분에서 호스트의 현재 IP 주소 및 네트워크 마스크 정보를 가져오는 방법을 살펴보았다. 이 정보를 사용하여 네트워크의 모든 호스트를 찾는 데 필요한 nmap의 기본 검색 매개변수를 설정할 수 있다. 이 정보를 지정하려면 CIDR 형식의 주소를 사용해야 한다. CIDR 형식은 호스트의 IP 주소와 네트워크 마스크의 비트 수를 사용하여 네트워크의 범위를 결정한다.
예제 호스트에서 192.168.1.25는 IP 주소이고 네트워크 마스크는 255.255.252.0이다. 이는 22비트에 해당한다. 즉, 첫 번째 부분에 8비트, 두 번째 부분에 8비트 그리고 세 번째 부분에 6비트가 해당한다.
이 주소를 사용하여 nmap을 실행하면 범위 내의 모든 단일 IP 주소(예를 들어, 192.168.0.0과 192.168.3.255 사이의 모든 주소)에 대한 검색이 수행되고 응답하는 호스트가 확인된다.
표준 ping 프로토콜을 사용하는 테스트나 다른 네트워크 포트를 시도하는 강력한 테스트(ping 프로토콜을 사용할 수 없는 경우)를 포함한 여러 가지 테스트를 수행할 수 있다. 예를 들어, ping 테스트를 수행하면 Listing 17과 같은 호스트 목록이 표시된다.
Listing 17. nmap을 실행하여 IP 주소 범위 검색하기
$ nmap -sP 192.168.1.25/22 Starting Nmap 4.76 ( http://nmap.org ) at 2009-03-24 15:59 GMT Host 192.168.0.1 appears to be up. Host bear.mcslp.pri (192.168.0.2) appears to be up. Host narcissus.mcslp.pri (192.168.0.3) appears to be up. Host 192.168.0.10 appears to be up. Host 192.168.0.27 appears to be up. Host sulaco.mcslp.pri (192.168.0.101) appears to be up. Host nautilus.wireless.mcslp.pri (192.168.0.109) appears to be up. Host 192.168.1.1 appears to be up. Host 192.168.1.25 appears to be up. Host gentoo1.vmbear.mcslp.pri (192.168.1.52) appears to be up. Host gentoo2.vmbear.mcslp.pri (192.168.1.53) appears to be up. Nmap done: 1024 IP addresses (11 hosts up) scanned in 5.78 seconds |
ping 검사를 수행하면 네트워크에 있는 다른 시스템을 매우 빠르게 확인할 수 있다. 이 경우에는 11개의 호스트가 검색되었지만 이들 중 일부 호스트는 이름을 다시 확인할 수 없다. 이는 DNS 구성에 오류가 있음을 나타낸다. 일부 시스템에서는 역방향 조회(IP 주소로 이름을 확인하는 조회)를 사용하여 클라이언트 IP 주소가 변조되지 않았는지 확인하는 보안 검사를 수행하므로 이 오류는 수정되어야 한다.
네트워크에 있는 다른 서비스 찾기
ping 검사가 유용하기는 하지만 개별 시스템에서 실제로 노출하고 있는 서비스를 알고 싶을 때는 TCP 검사를 사용해야 한다. TCP 검사를 수행하면 nmap이 목록 내에 있는 각 호스트에서 TCP/IP 프로토콜을 사용하는 포트를 열려고 시도하므로 더 많은 시간이 소요된다. 이 검사는 네트워크에 있는 호스트를 표시하고 각 호스트의 열려 있는 포트에 대한 세부 정보를 제공하려는 경우에 효과적이다. Listing 18에서 이 검사의 출력 예제를 볼 수 있다.
Listing 18. TCP 검사 사용하기
$ nmap -sT 192.168.1.25/22 Starting Nmap 4.76 ( http://nmap.org ) at 2009-03-24 16:03 GMT Interesting ports on 192.168.0.1: Not shown: 997 closed ports PORT STATE SERVICE 80/tcp open http 8080/tcp open http-proxy 49153/tcp open unknown Interesting ports on bear.mcslp.pri (192.168.0.2): Not shown: 987 closed ports PORT STATE SERVICE 22/tcp open ssh 25/tcp open smtp 53/tcp open domain 80/tcp open http 111/tcp open rpcbind 143/tcp open imap 443/tcp open https 902/tcp open iss-realsecure 993/tcp open imaps 2000/tcp open callbook 2049/tcp open nfs 3128/tcp open squid-http 3306/tcp open mysql Interesting ports on narcissus.mcslp.pri (192.168.0.3): Not shown: 982 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 88/tcp open kerberos-sec 106/tcp open pop3pw 111/tcp open rpcbind 311/tcp open asip-webadmin 389/tcp open ldap 548/tcp open afp 625/tcp open apple-xsrvr-admin 749/tcp open kerberos-adm 1021/tcp open unknown 1022/tcp open unknown 3659/tcp open unknown 3689/tcp open rendezvous 4111/tcp open unknown 5900/tcp open vnc 8086/tcp open unknown 8087/tcp open unknown Interesting ports on 192.168.0.10: Not shown: 997 closed ports PORT STATE SERVICE 23/tcp open telnet 80/tcp open http 443/tcp open https Interesting ports on 192.168.0.27: Not shown: 999 closed ports PORT STATE SERVICE 22/tcp open ssh Interesting ports on sulaco.mcslp.pri (192.168.0.101): Not shown: 995 closed ports PORT STATE SERVICE 22/tcp open ssh 88/tcp open kerberos-sec 548/tcp open afp 631/tcp open ipp 2170/tcp open unknown Interesting ports on nautilus.wireless.mcslp.pri (192.168.0.109): Not shown: 995 closed ports PORT STATE SERVICE 22/tcp open ssh 88/tcp open kerberos-sec 111/tcp open rpcbind 1001/tcp open unknown 5900/tcp open vnc Interesting ports on 192.168.1.1: Not shown: 995 closed ports PORT STATE SERVICE 21/tcp open ftp 22/tcp open ssh 23/tcp open telnet 80/tcp open http 5431/tcp open unknown Interesting ports on 192.168.1.25: Not shown: 997 closed ports PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind 4045/tcp open lockd Interesting ports on gentoo1.vmbear.mcslp.pri (192.168.1.52): Not shown: 997 closed ports PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind 3128/tcp open squid-http Interesting ports on gentoo2.vmbear.mcslp.pri (192.168.1.53): Not shown: 998 closed ports PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind Nmap done: 1024 IP addresses (11 hosts up) scanned in 32.27 seconds |
이 출력을 보면 다양한 서비스를 제공하는 수많은 서버가 네트워크에 있다는 것을 알 수 있다. 예를 들어, 192.168.0.1의 장치는 HTTP 및 HTTP 프록시 서비스를 제공한다. 또한 bear.mcslp.pri는 http뿐만 아니라 smtp, imap, nfs 및 MySQL 서비스도 제공한다.
이러한 서비스에 대한 구체적인 정보를 확인하려는 경우에는 다시 한번 nmap을 버전 인수와 함께 사용하여 특정 호스트에 열려 있는 프로토콜 및 포트에 대한 구체적인 버전 정보 목록을 확인할 수 있다.
예를 들어, 메인 서버처럼 보이는 호스트(bear)를 검사해 보면 이러한 각 포트에서 실행되고 있는 서비스를 매우 정확히 파악할 수 있다(Listing 19 참조).
Listing 19. 버전 인수와 함께 nmap 사용하기
$ nmap -sT -sV bear Starting Nmap 4.76 ( http://nmap.org ) at 2009-03-24 16:17 GMT Interesting ports on localhost (127.0.0.1): Not shown: 985 closed ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 5.1 (protocol 2.0) 25/tcp open smtp Postfix smtpd 53/tcp open domain ISC BIND 9.4.3-P1 111/tcp open rpcbind 143/tcp open imap Cyrus IMAP4 2.3.13-Gentoo 443/tcp open ssl/http Apache httpd 783/tcp open spamassassin SpamAssassin spamd 902/tcp open ssl/vmware-auth VMware Authentication Daemon 1.10 (Uses VNC) 993/tcp open ssl/imap Cyrus imapd 2000/tcp open sieve Cyrus timsieved 2.3.13-Gentoo (included w/cyrus imap) 2049/tcp open rpcbind 3128/tcp open http-proxy Squid webproxy 2.7.STABLE6 3306/tcp open mysql MySQL 5.0.60-log 10024/tcp open smtp amavisd smtpd 10025/tcp open smtp Postfix smtpd Service Info: Hosts: gendarme.mcslp.com, bear, 127.0.0.1 Service detection performed. Please report any incorrect results at http://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 12.12 seconds |
이 출력에서는 수많은 특정 서비스를 볼 수 있으며, 각 포트에서 제공하는 버전 정보뿐 아니라 애플리케이션 정보까지도 확인할 수 있다.
네트워크에서 식별되지 않은 호스트 확인하기
네트워크에 있는 호스트를 검색한 후 호스트에 대한 정보 특히, 즉시 인식되지 않는 호스트에 대한 정보를 확인할 수 있다. TCP 포트 검사는 호스트에서 지원하고 있는 서비스를 보여 주기는 하지만 반드시 모든 정보를 보여 주는 것은 아니다. 일부 장치 및 시스템의 경우에는 네트워크의 서비스를 즉시 확인할 수 없는 방식으로 포트를 노출하기도 하며 더 나아가 노출하지 않을 수도 있다.
nmap 운영 체제 검사는 열려 있는 포트를 검사한 후 다양한 서비스가 실행되고 있는 운영 체제를 확인한다. 이 기능은 네트워크에서 열려 있는 포트와 새 장치가 있는 서버를 식별하는 기능과는 다르다.
예를 들어, Listing 20에서와 같이 bear라는 서버에 대해 운영 체제 식별을 실행하면 일반적인 Linux 버전이 시스템에서 실행되고 있다는 것을 식별할 수 있으며 이는 해당 시스템이 표준 컴퓨터임을 나타낸다.
Listing 20. nmap 운영 체제 검사
# nmap -sT -O bear Starting Nmap 4.76 ( http://nmap.org ) at 2009-03-24 16:20 GMT Interesting ports on localhost (127.0.0.1): Not shown: 985 closed ports PORT STATE SERVICE 22/tcp open ssh 25/tcp open smtp 53/tcp open domain 111/tcp open rpcbind 143/tcp open imap 443/tcp open https 783/tcp open spamassassin 902/tcp open iss-realsecure 993/tcp open imaps 2000/tcp open callbook 2049/tcp open nfs 3128/tcp open squid-http 3306/tcp open mysql 10024/tcp open unknown 10025/tcp open unknown Device type: general purpose Running: Linux 2.6.X OS details: Linux 2.6.17 - 2.6.25 Network Distance: 0 hops OS detection performed. Please report any incorrect results at http://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 1.71 seconds |
OS 검사는 완벽하지 않으며 finger printing 기술을 사용하여 열려 있는 포트 및 리턴된 버전 정보의 의미를 확인한다. 예를 들어, Listing 21의 검사에서는 포트 유형을 기반으로 잠재적 운영 체제의 수를 식별한다.
Listing 21. 잠재적 운영 체제의 수를 식별하는 검사
# nmap -sT -O some.faroffhost.com Starting Nmap 4.76 ( http://nmap.org ) at 2009-03-24 16:23 GMT Interesting ports on some.faroffhost.com (205.196.217.20): Not shown: 976 closed ports PORT STATE SERVICE 21/tcp open ftp 22/tcp open ssh 25/tcp open smtp 110/tcp open pop3 111/tcp filtered rpcbind 113/tcp open auth 135/tcp filtered msrpc 139/tcp filtered netbios-ssn 143/tcp open imap 548/tcp open afp 554/tcp open rtsp 555/tcp open dsf 587/tcp open submission 687/tcp open unknown 993/tcp open imaps 995/tcp open pop3s 1720/tcp filtered H.323/Q.931 5222/tcp open unknown 5269/tcp open unknown 5666/tcp open unknown 7070/tcp open realserver 8000/tcp open http-alt 8001/tcp open unknown 8649/tcp open unknown Device type: print server|general purpose|storage-misc|WAP|switch|specialized Running (JUST GUESSING) : HP embedded (92%), Linux 2.6.X|2.4.X (92%), Buffalo embedded (91%), Acorp embedded (89%), Actiontec Linux 2.4.X (89%), Linksys embedded (89%), Netgear embedded (89%), Infoblox NIOS 4.X (89%) Aggressive OS guesses: HP 4200 PSA (Print Server Appliance) model J4117A (92%), Linux 2.6.20 (Ubuntu 7.04 server, x86) (92%), Linux 2.6.9 (92%), Buffalo TeraStation NAS device (91%), Linux 2.6.18 (CentOS 5.1, x86) (91%), OpenWrt 7.09 (Linux 2.4.34) (90%), Acorp W400G or W422G wireless ADSL modem (MontaVista Linux 2.4.17) (89%), HP Brocade 4100 switch; or Actiontec MI-424-WR, Linksys WRVS4400N, or Netgear WNR834B wireless broadband router (89%), HP Brocade 4Gb SAN switch (89%), Infoblox NIOS Release 4.1r2-5-22263 (89%) No exact OS matches for host (test conditions non-ideal). Network Distance: 18 hops OS detection performed. Please report any incorrect results at http://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 23.66 seconds |
nmap 검사는 로컬 및 원격 네트워크 둘 다에 대해 실행할 필요는 없다. 위 원격 테스트에서 nmap은 패킷이 대상 시스템에 도달하기 전까지 통과해야 하는 다양한 시스템을 확인했다. 사용자의 시스템과 다른 시스템 사이에 있는 다양한 장치를 파악하는 작업은 네트워크 레이아웃을 이해하고 파악하는 과정의 마지막 단계이다.
네트워크 구조 결정하기
IP 네트워크 패킷이 네트워크에서 전송될 경우, 시스템이 패킷을 다른 네트워크 또는 시스템으로 전달할 때마다 특수 카운터가 증가된다. 패킷 전달은 여러 다양한 시스템에서 발생한다. 여러 네트워크 스위치가 함께 연결되어 있는 경우 각 허브는 자신을 새 장치로 식별할 수 있다. 또한 무선 액세스 포인트와 기존 라우터 모두 패킷을 전달하는 장치이므로 패킷의 네트워크 경로의 일부로 간주된다.
대부분의 네트워크 환경에서 로컬 네트워크에 있는 허브, 스위치 및 기타 구성 요소는 이 값을 증가시키지 않는다. 하지만 외부 네트워크로까지 시선을 넓히면 네트워크 규모가 더 커지고 복잡해지므로 개별 패킷의 경로를 이해할 수 있다면 성능 및 연결 문제를 식별하는 데 많은 도움이 된다.
호스트와의 통신 경로에 대한 정보를 표시하는 데 주로 사용되는 도구는 traceroute이다. 이 도구는 현재 호스트에서 대상까지의 지정된 경로 내에 있는 각 호스트의 IP 주소를 확인한다. 대상 호스트가 로컬 호스트 자신이면 직접 경로로 표시된다(Listing 22 참조).
Listing 22. traceroute 사용하기
$ traceroute solaris2 traceroute to solaris2 (192.168.1.25), 30 hops max, 40 byte packets 1 solaris2.mcslp.pri (192.168.1.25) 0.651 ms 0.892 ms 0.969 ms |
Listing 23에서는 로컬 라우터나 브리지를 통해 액세스할 수 있는 로컬 네트워크에 있는 호스트를 보여 준다.
Listing 23. 로컬 네트워크에 있는 호스트
$ traceroute gentoo1 traceroute to gentoo1 (192.168.1.52), 30 hops max, 40 byte packets 1 gendarme.mcslp.pri (192.168.0.1) 3.163 ms 3.159 ms 6.618 ms 2 gentoo1.mcslp.pri (192.168.1.52) 34.336 ms 34.341 ms 34.341 ms |
원격 네트워크에 대한 연결은 패킷이 통과하게 되는 각 라우터와 단계를 보여 준다(Listing 24 참조.
Listing 24. 원격 네트워크 연결
$ traceroute www.ibm.com
traceroute to www.ibm.com (129.42.58.216), 30 hops max, 40 byte packets
1 gendarme.mcslp.pri (192.168.0.1) 3.163 ms 3.159 ms 6.618 ms
2 gauthier-dsl1.hq.zen.net.uk (62.3.82.17) 34.336 ms 34.341 ms 34.341 ms
3 lotze-ge-0-0-1-136.hq.zen.net.uk (62.3.80.137) 37.581 ms 47.276 ms 50.548 ms
4 nietzsche-ae2-0.ls.zen.net.uk (62.3.80.70) 43.945 ms 47.239 ms 50.529 ms
5 nozick-ge-3-1-0-0.ls.zen.net.uk (62.3.80.74) 55.343 ms 55.341 ms 55.339 ms
6 lorenz-ge-3-0-0-0.te.zen.net.uk (62.3.80.78) 66.347 ms 63.118 ms 63.105 ms
7 82.195.188.13 (82.195.188.13) 146.039 ms 118.175 ms 124.532 ms
8 sl-bb22-lon-8-0.sprintlink.net (213.206.128.60) 50.460 ms 47.273 ms 40.991 ms
9 sl-bb20-lon-12-0.sprintlink.net (213.206.128.52) 47.107 ms 47.094 ms 43.711 ms
10 sl-crs2-nyc-0-5-3-0.sprintlink.net (144.232.9.164) 111.579 ms 113.173 ms
113.159 ms
11 144.232.18.238 (144.232.18.238) 116.353 ms 111.633 ms 111.619 ms
12 0.xe-5-0-1.XL3.NYC4.ALTER.NET (152.63.3.125) 114.812 ms 111.788 ms 115.000 ms
13 0.so-7-1-0.XT3.STL3.ALTER.NET (152.63.0.6) 151.969 ms 142.573 ms 142.574 ms
14 POS6-0.GW8.STL3.ALTER.NET (152.63.92.37) 142.552 ms 253.001 ms 252.986 ms
15 ibm-gw.customer.alter.net (65.206.180.74) 179.655 ms 228.775 ms 228.751 ms
16 10.16.255.10 (10.16.255.10) 145.847 ms 139.310 ms 142.509 ms
17 * * *
18 129.42.58.216 (129.42.58.216) 143.118 ms 141.181 ms 141.152 ms
|
호스트 목록을 확인하는 nmap과 함께 이 방법을 사용하면 네트워크에 있는 호스트에 대한 정보와 이러한 시스템에 도달하는 데 사용되는 라우터 및 시스템에 대한 정보를 훨씬 더 자세히 볼 수 있다.
결론
이 튜토리얼에서는 네트워크에 있는 호스트, 이러한 호스트에 액세스하는 방법, 연결되어 있는 장치 및 시스템, 제공되는 서비스 및 시스템 등에 대한 다양한 정보를 확인하는 데 사용할 수 있는 여러 가지 UNIX 도구 및 기술을 살펴보았다.
이제 이러한 기술을 통해 UNIX 환경에 액세스하여 네트워크 구성을 확인할 수 있어야 하며, 필요한 정보를 기록하여 문제점 및 그 이유를 파악하고 해결 방법까지도 알아낼 수 있어야 한다.
기사의 원문보기
피드 구독하기:
글 (Atom)